Esse post vai ser bem parecido com o que já escrevi aqui sobre como configurar o GoldenGate for Bigdata para escrever no Streaming, a diferença aqui é que vamos usar tudo como serviço, tanto o for oracle quanto o for bigdata.
Arquitetura
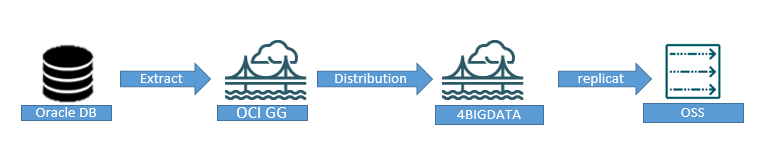
Registrando targets
Com o lançamento do Goldengate Big Data como serviço, temos um novo menu chamado Connections e nele temos diversas opções de tipos de conexão:
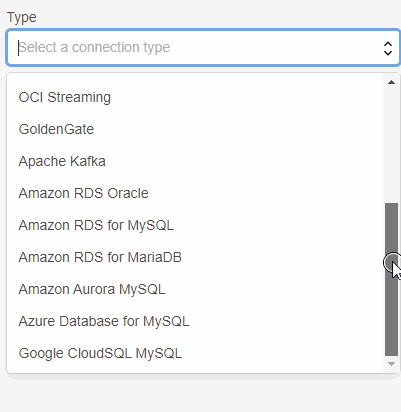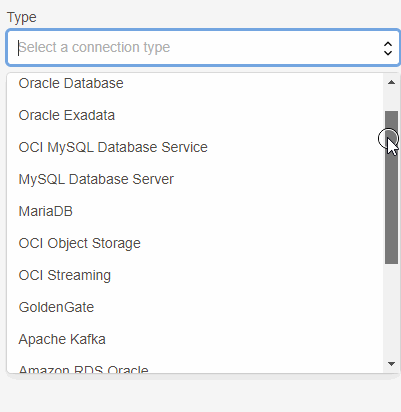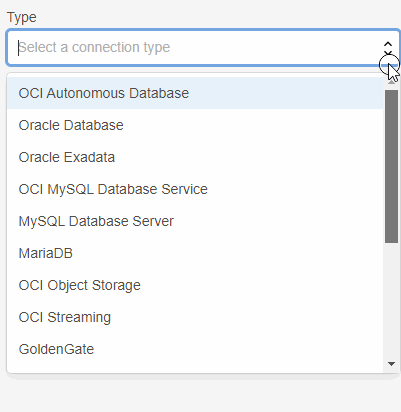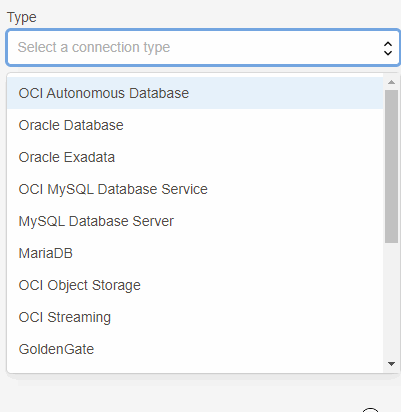
Aqui além da conexão com o banco de dados (source) vamos adicionar duas outras, uma do tipo OCI Streaming e outra do tipo Goldengate.
Na conexão do tipo Goldengate, você pode selecionar um deployment que já esteja criado(se for um deployment com endpoint público) ou entrar as informações de conexão caso ele esteja em um rede privada, vale lembrar que a rede que você seleciona quando marca para a conexão via private endpoint precisa conseguir chegar no deployment do goldengate, caso você precise acessar um deployment privado, coloque a Console URL campo Host e a porta 443 além do IP privado.
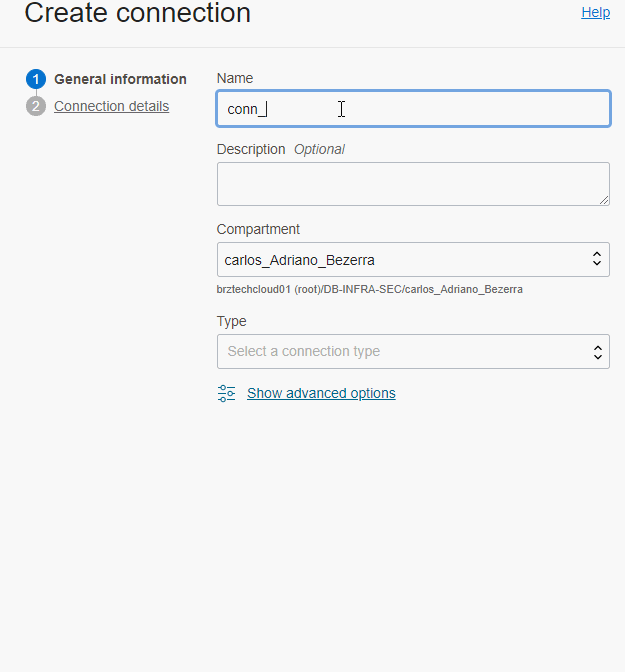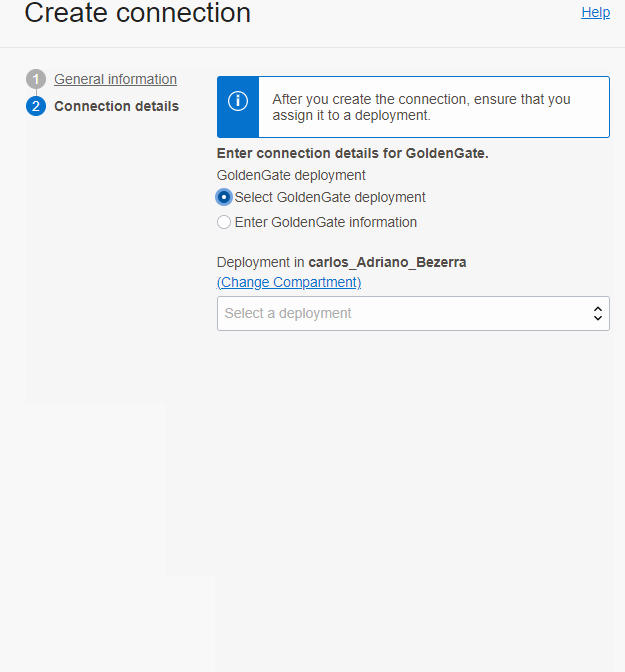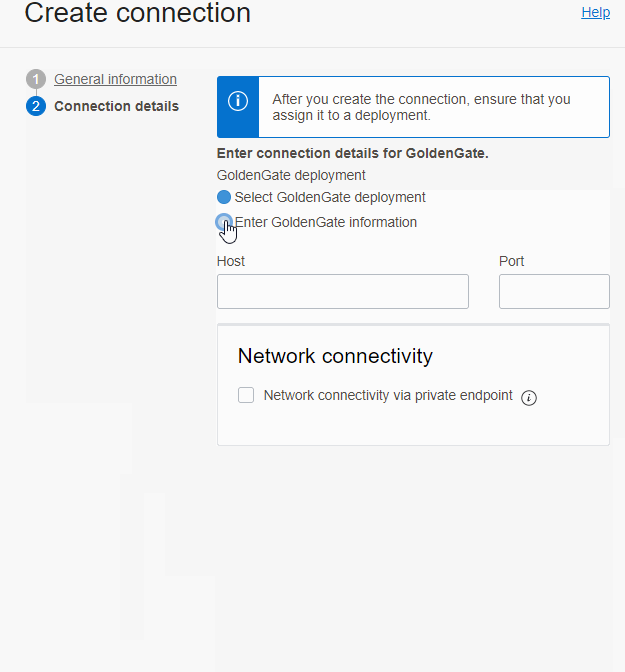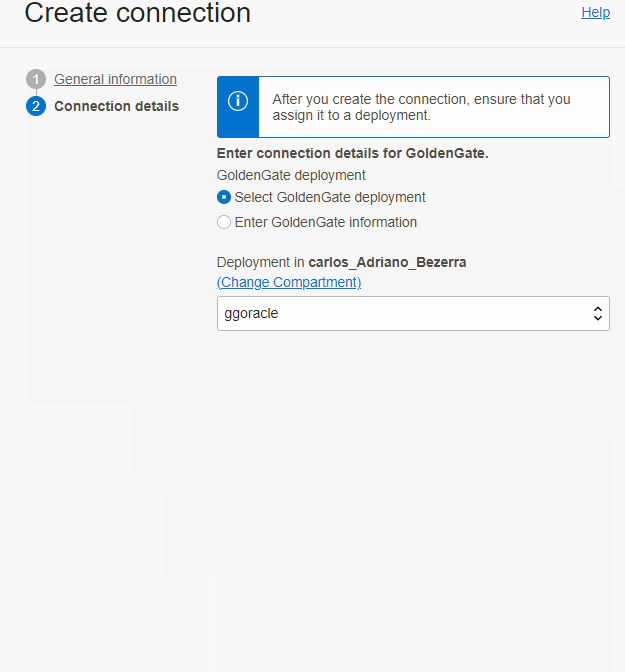
Depois que a conexão está criada, você precisa vincular ela ao deployment que vai usa-la indo na conexão e Assign Deployment:
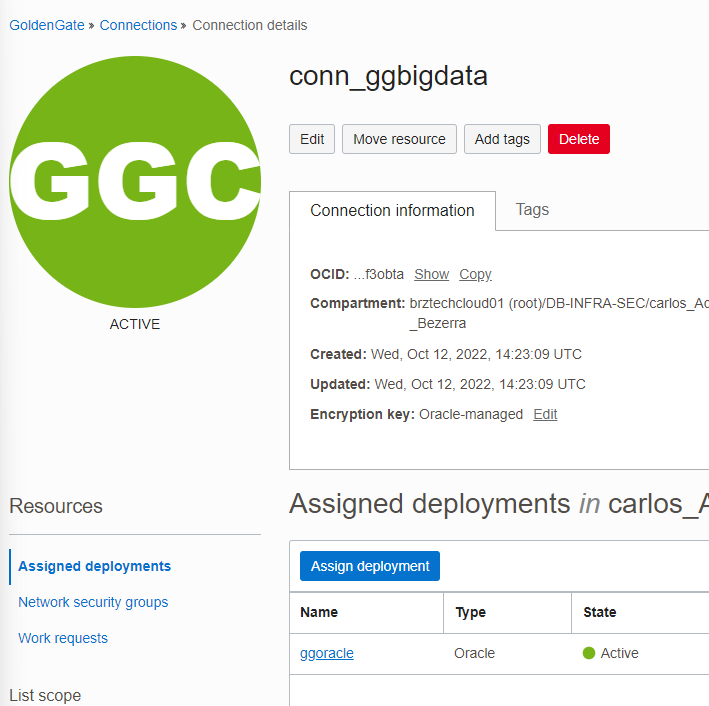
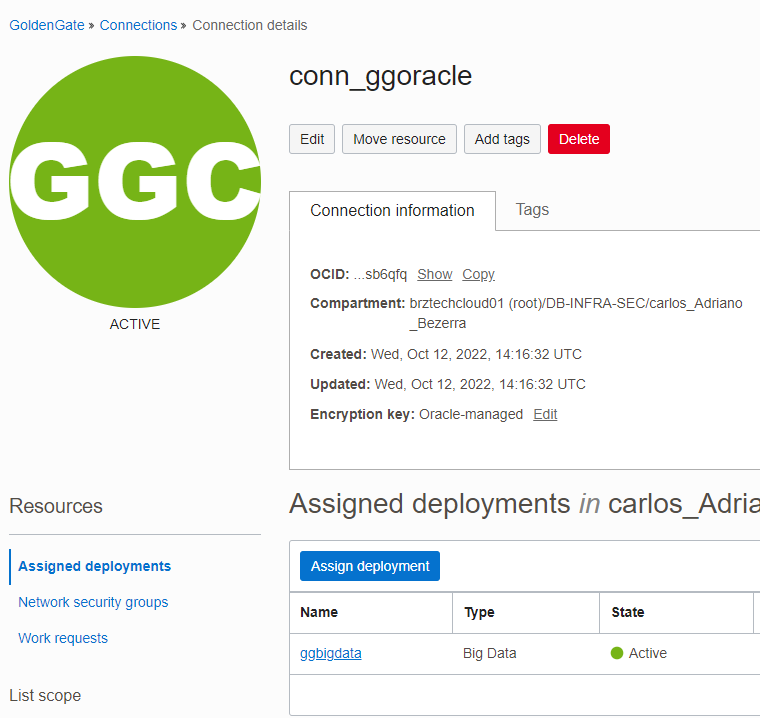
Dessa forma um deployment vai ter a possibilidade de se conectar ao outro, uma dica importante é que qualquer alteração da conexão (endereço, senha, etc) deve ser feita na console do OCI e não dentro do Goldengate.
Na conexão do tipo OCI Streaming você precisa usar um usuário local para a autenticação e seu usuário deve ter o padrão tenancy/usuario/stream_pool_ocid:
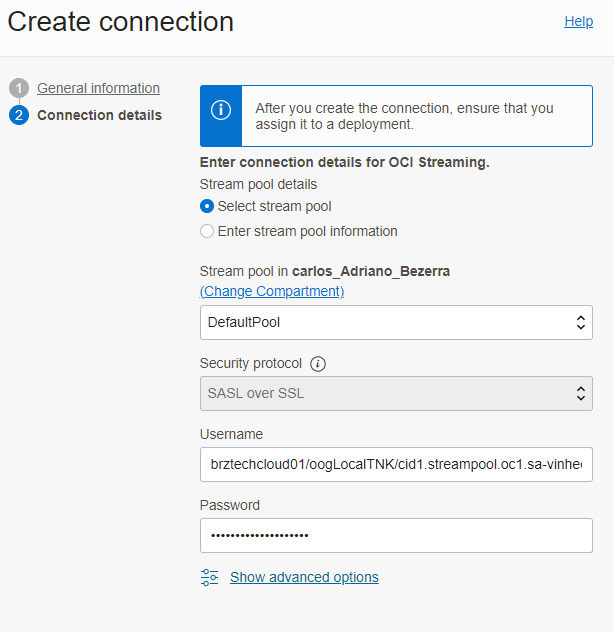
Essa conexão precisa ser vinculada apenas ao deployment do big data.
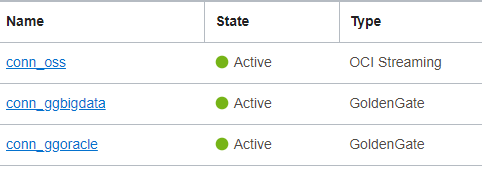
No final vamos ter 3 conexões(além é claro do source):
Extract
Assim como no outro artigo, não vou me aprofundar muito aqui, o meu é bem simples:
EXTRACT eKafka USERIDALIAS atp_vcp DOMAIN OracleGoldenGate EXTTRAIL extkafka/qq ddl include mapped ddloptions report TRANLOGOPTIONS SOURCE_OS_TIMEZONE GMT-3 TABLE TNK_SRC.INILOAD; tranlogoptions excludeuser ggadmin
Distribution/Receive Service
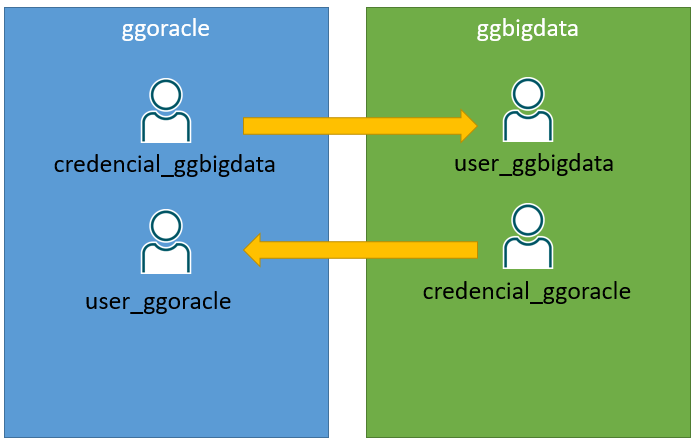
Para a conexão entre os deployments, além da conexão criada e atribuída para o deployment, você precisa dentro do deployment for Oracle criar um usuário para o deployment for Bigdata e o contrário também e após isso criar uma credencial:
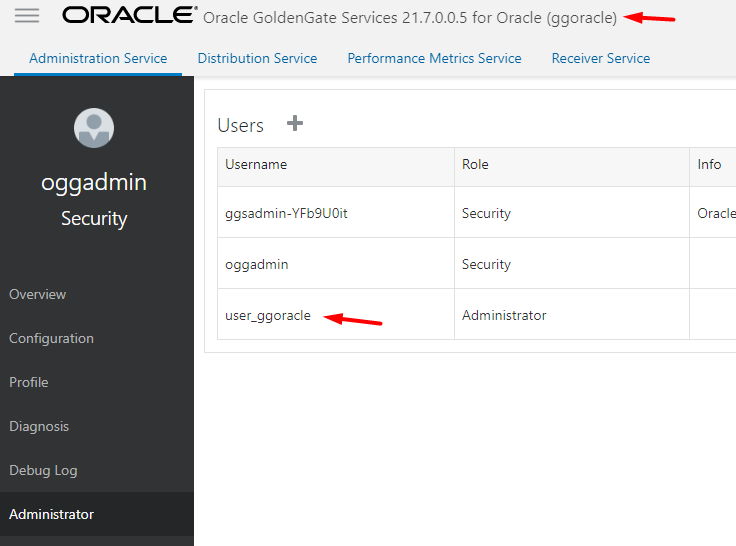
Para criar o usuário você precisa ir em Administration Service > Administrator-> Users:
E para criar a credencial você precisa ir em Administrator Service -> Configuration -> Credentials :
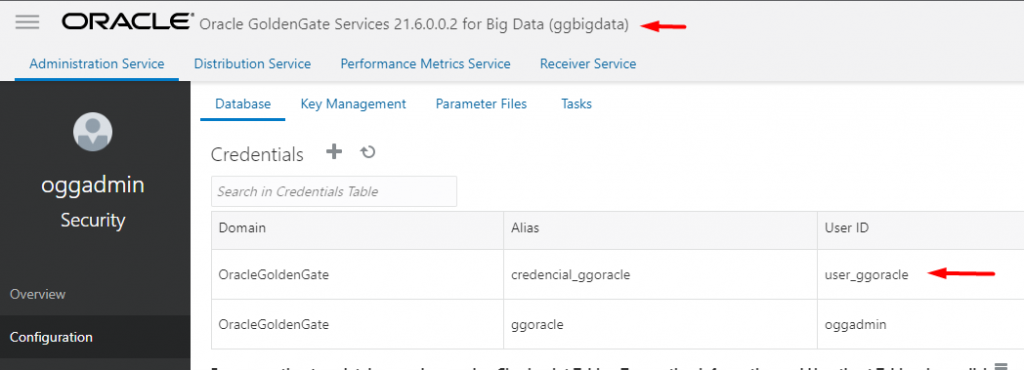
Colocar o User ID com o mesmo nome do usuário criado e também sua senha.
Agora com as credenciais criadas já podemos criar nosso Distribution Service ou Receive Service, a diferença entre eles é de onde a conexão vai ser originada, por ex. se você precisa enviar os trails do ggoracle para o ggbigdata você cria um Distribution Service, agora se você deseja copiar os trails do ggoracle para o ggbigdata você cria um Receive Service.
No meu caso vou enviar os trails que estão no meu ggoracle para o ggbigdata (com um Distribution Service):
A primeira parte da configuração está relacionada com a origem, basicamente você deve escolher qual o Extract/Trail vai ser enviado, depois você precisa configurar a parte de autenticação no target, aqui vamos usar a modalidade wss onde precisamos passar a URL do ggbigdata (mesmo que ele seja privado, toda configuração deve ser feita com ela e não com o IP), porta que por padrão é a 443, diretório dos trails, trail file no destino o Domain e a credencial criada para a conexão, depois disso basta clicar em Create and Run no fim da página.
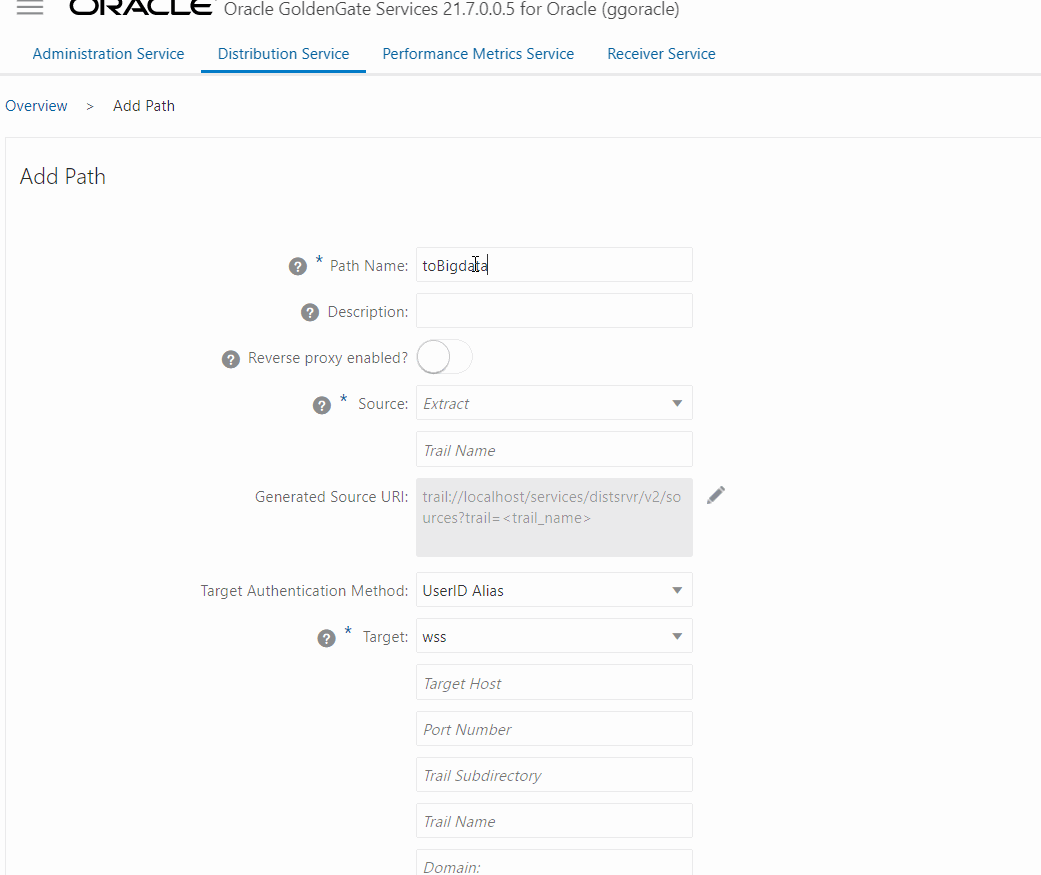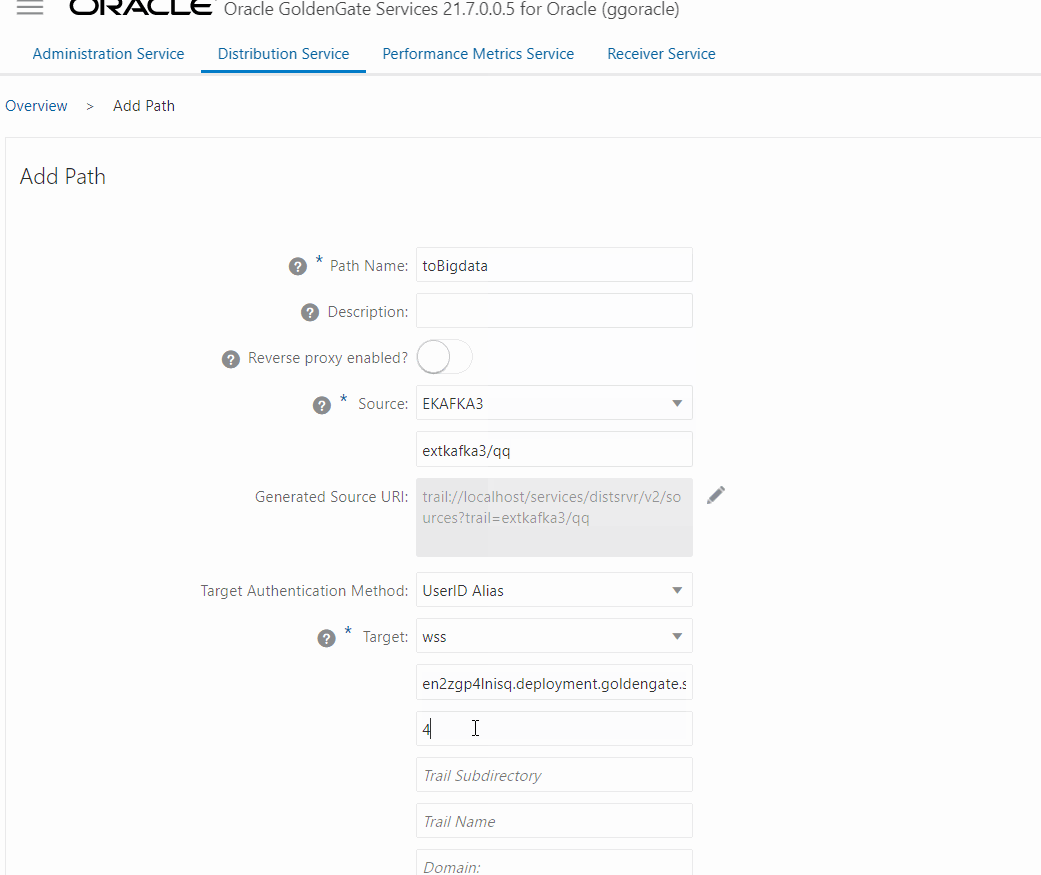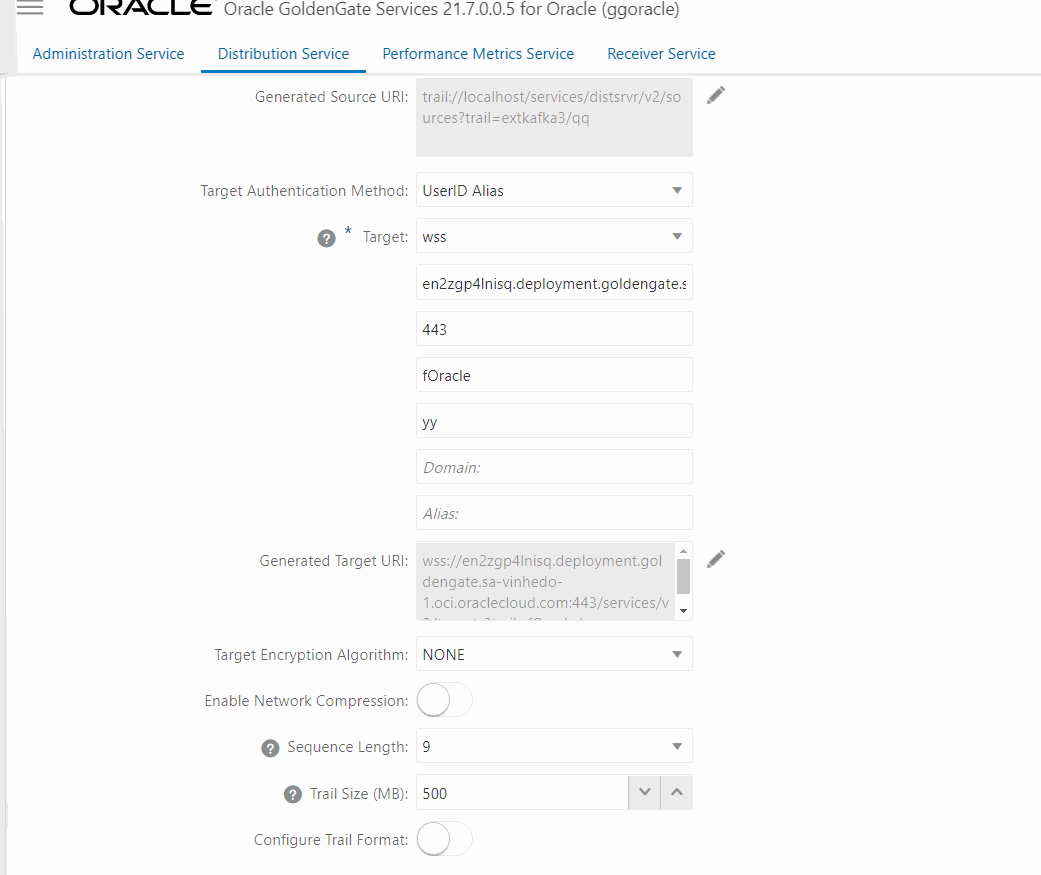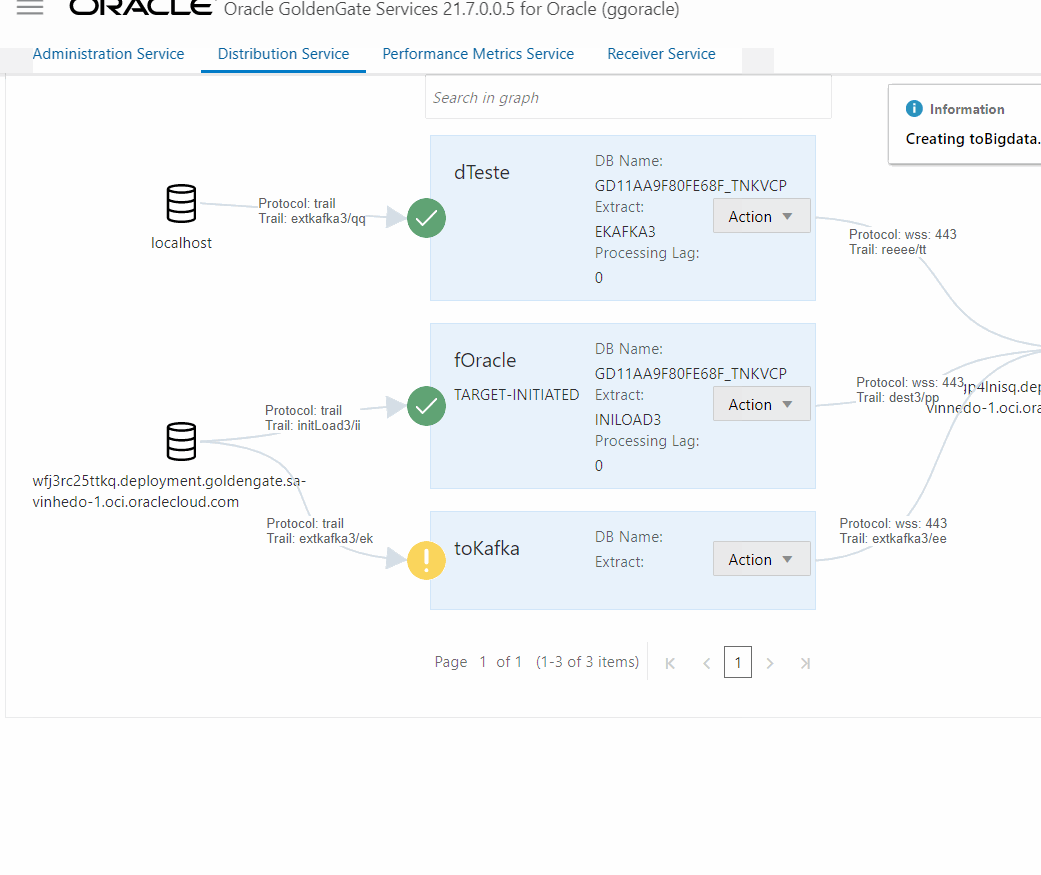
Se todas as informações estiverem corretas, logo do Distribution Path deve ser criado e ficar verde:
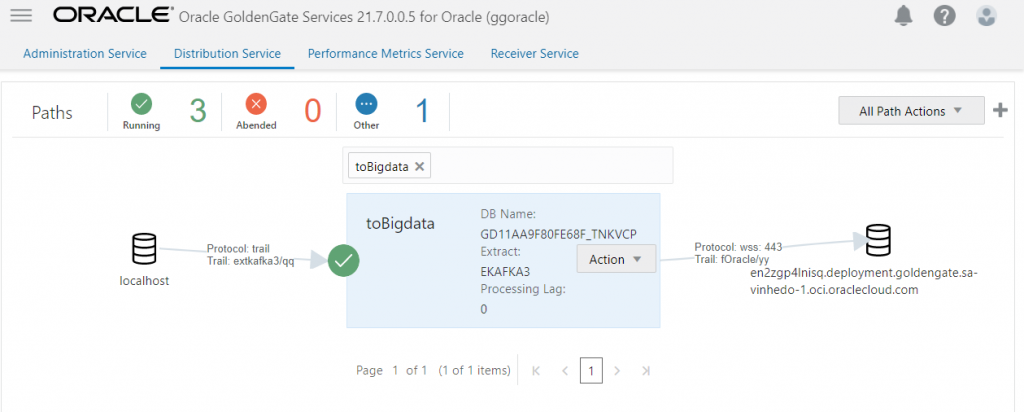
E no deploy do Bigdata você deve ver um Receive Path:
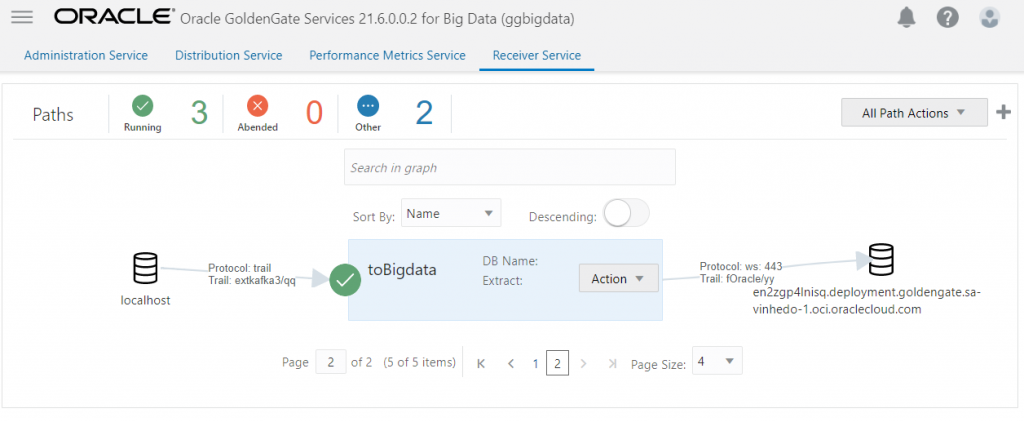
Replicat
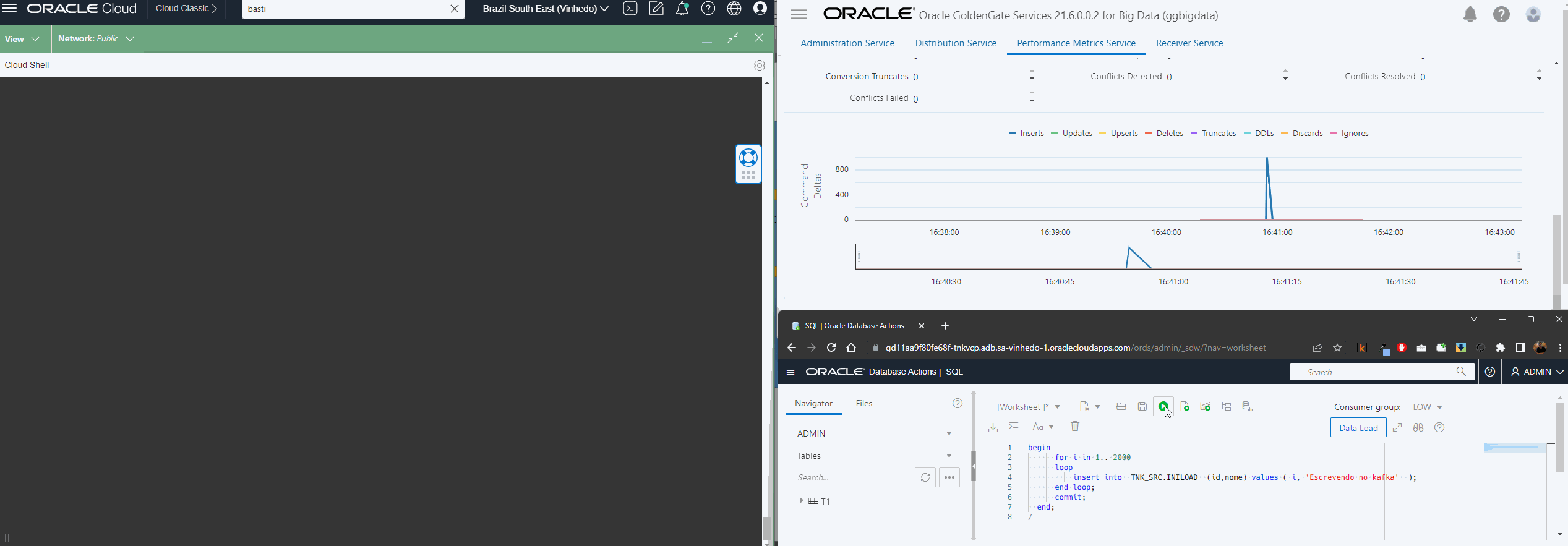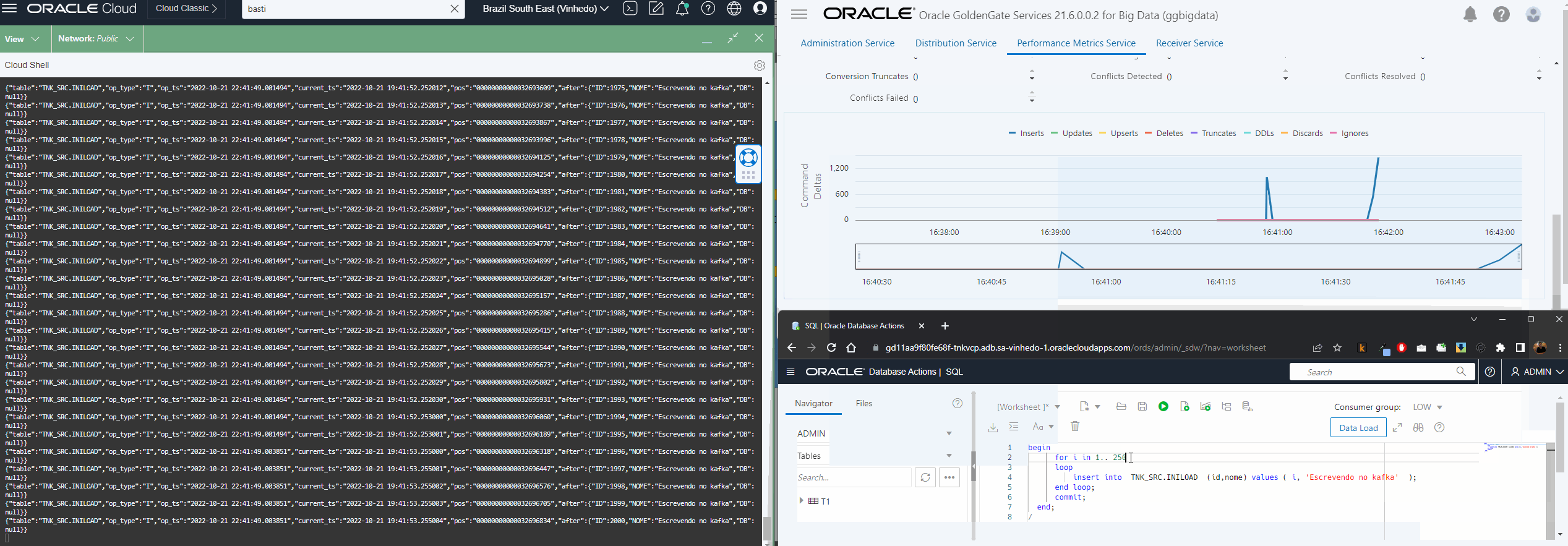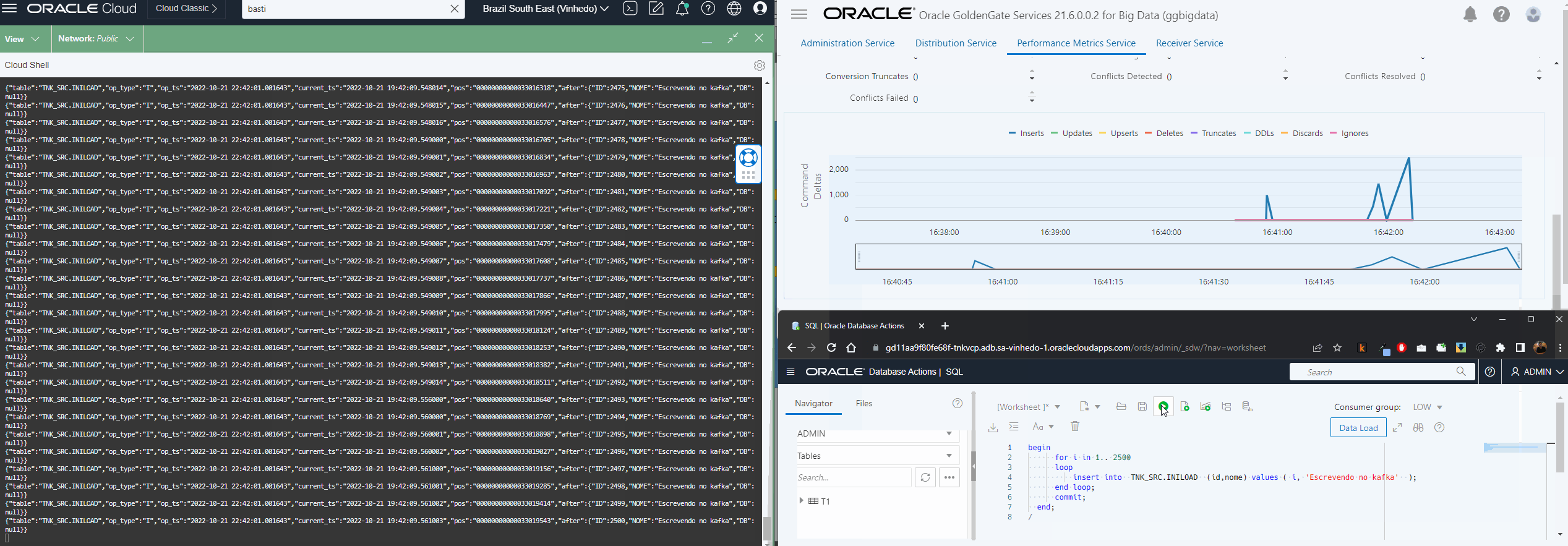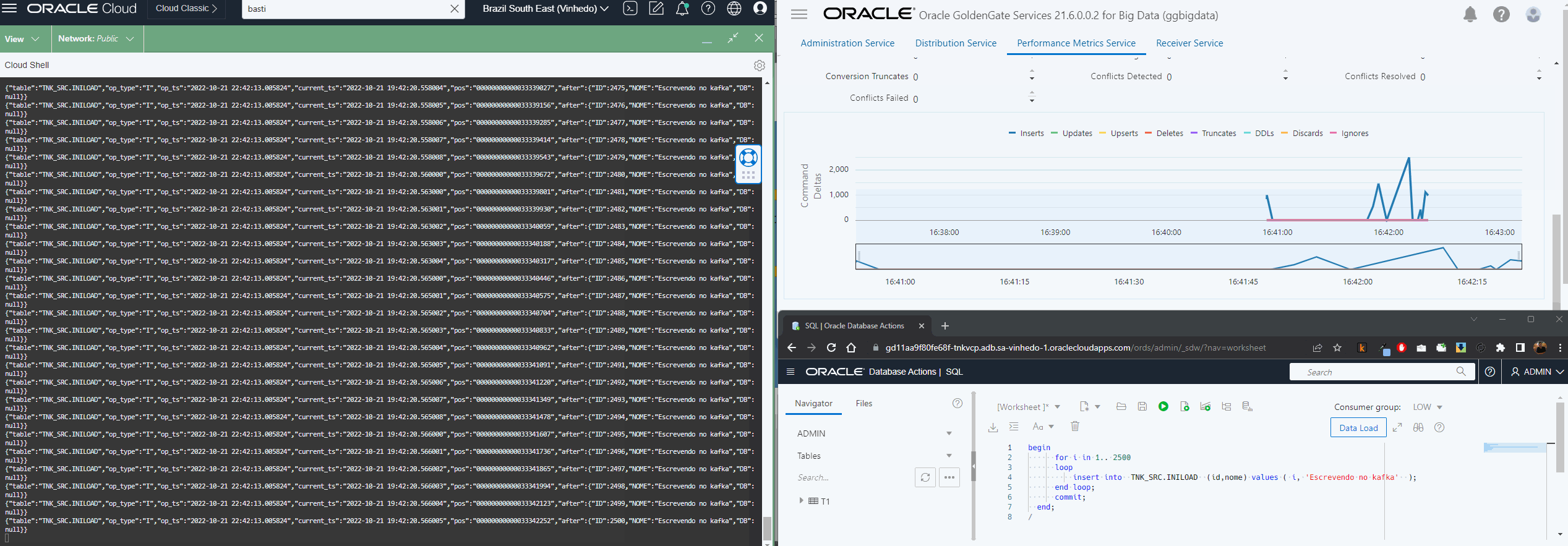
Agora que já temos nosso Extract extraindo os dados da origem, nosso Distribution enviando os trails para o oggbigdata, vamos configurar a escrita no OSS usando o replicat.
Esse processo é bem simples de ser feito via console, a parte importante aqui é ter atribuído a conexão OSS no deploy do bigdata e no trail name especificar o trail que configurou no Distribution Path:
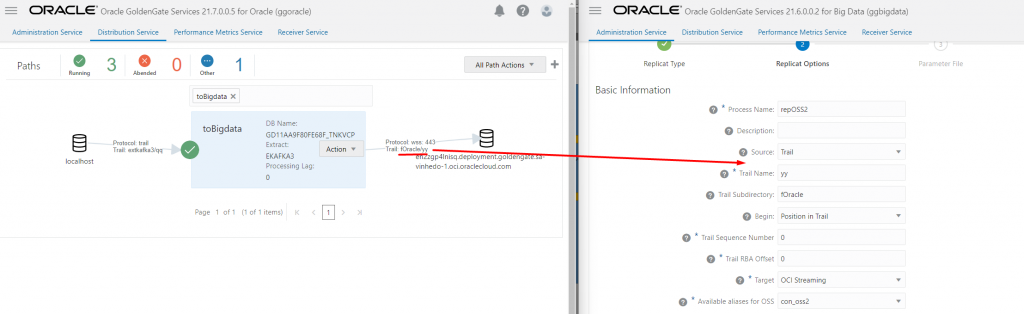
O resto do processo é bem parecido com o que já descrevi aqui, a principal diferença é que agora temos o parâmetro gg.handler.oss.connectionId que só existe no OCI GG.
# Properties file for Replicat repOSS2
# OSS Handler Template
gg.handlerlist=oss
gg.handler.oss.type=kafka
gg.handler.oss.connectionId=ocid1.goldengateconnection.oc1.sa-vinhedo-1.amaaaaaatXXXXXXXXXX
#TODO: Set the template for resolving the topic name.
gg.handler.oss.topicMappingTemplate=${fullyQualifiedTableName}
gg.handler.oss.keyMappingTemplate=${primaryKeys}
gg.handler.oss.mode=op
gg.handler.oss.format=json
gg.handler.oss.format.metaColumnsTemplate=${objectname[table]},${optype[op_type]},${timestamp[op_ts]},${currenttimestamp[current_ts]},${position[pos]}
gg.classpath=$THIRD_PARTY_DIR/kafka/*
jvm.bootoptions=-Xmx512m -Xms32m
Testando