
O OCI Streaming (ou OSS) é um serviço de stream de eventos compátivel com o Apache Kafka 100% gerenciado pela Oracle, nesse artigo demonstro como extrair dados de um banco Oracle (usando o GoldenGate) e escrever nele usando o GoldenGate for bigdata.
Nossa arquitetura

Extract/pump
Nosso extract/pump vai ser bem simples, aqui estou usando o parâmetro RMTTHOST para enviar o trail que é gerado pela extração para o servidor do Bigdata e extraindo todas as tabelas do schema HR:
EXTRACT pumposs RMTHOST IP_BIGDATA, MGRPORT 9013 RMTTRAIL /u02/trails/t1 PASSTHRU TABLE ORCL19_PDB1.HR.*;
OSS
Antes de configurarmos nosso replicat, precisamos criar e parametrizar nosso OSS.
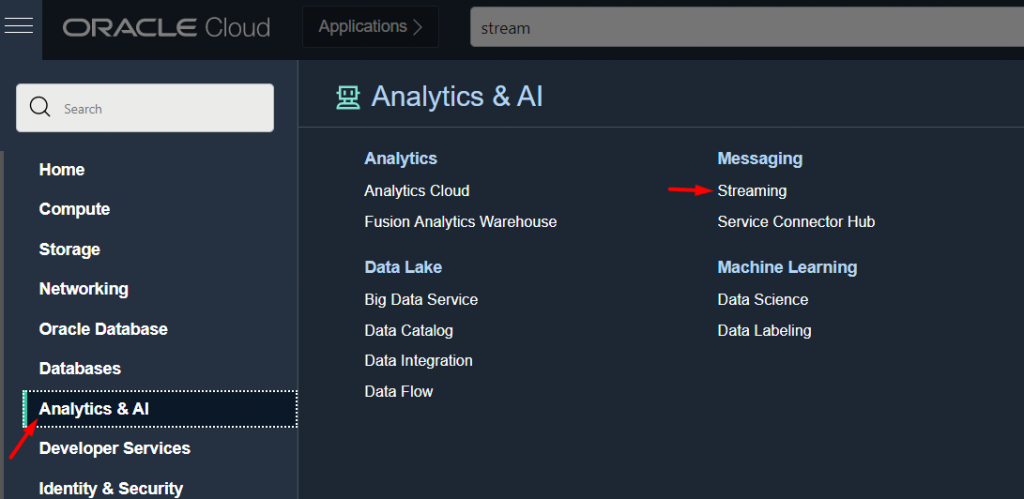
O primeiro passo é criar o Stream Pool, que serve para agrupar nossos Streams (tópicos do Kafka), aqui temos a opção de criar um Stream público ou Privado, para nosso exemplo vamos na modalidade pública e precisamos ir em Advanced e marcar a opção Auto Create Topics (senão para cada tabela você vai precisar criar o Stream na mão).
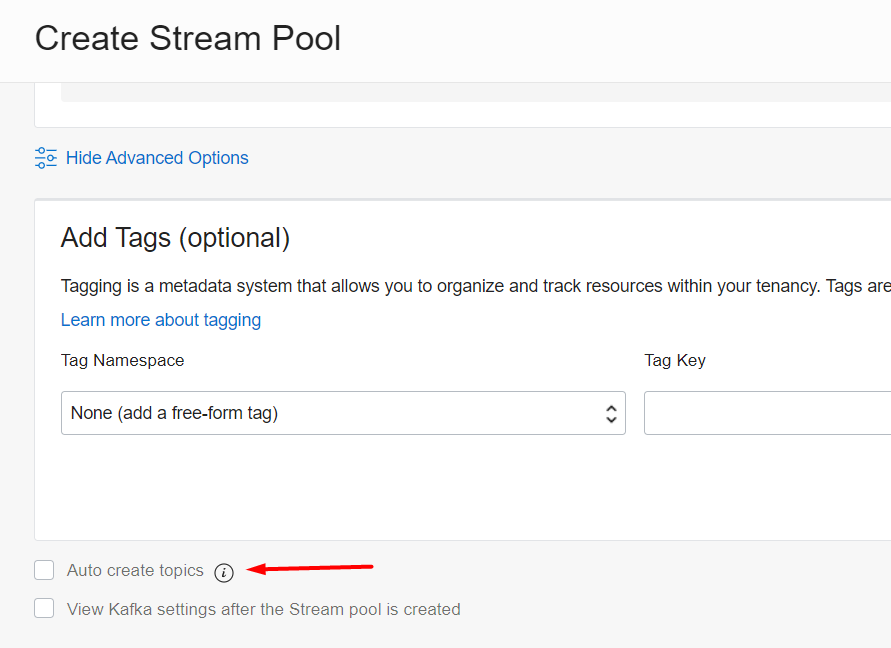
Depois que ele for criado, precisamos pegar as informações de login dentro dele (se você marcar a segunda opção View Kafka settings ele já vai te direcionar para a página) que fica no Stream Pool -> Kafka connection Settings:
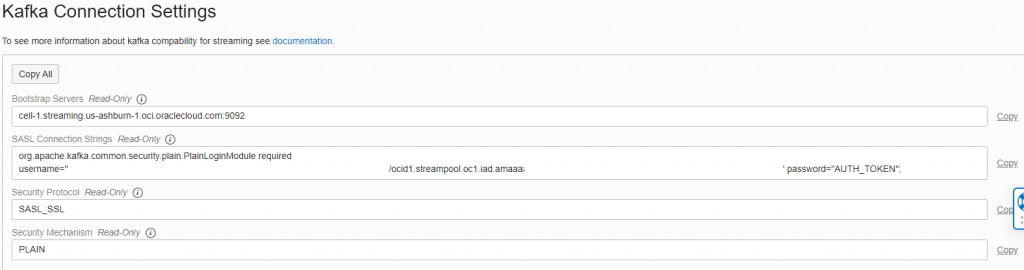
O seu usuário é essa string gigante mesmo que termina com o ocid do Stream Pool.
Configurando o GoldenGate for Big Data
Nesse exemplo estou usando o GoldenGate for Big Data do Marketplace na versão 21c, antigamente para cada conector do BigData, você precisava fazer o download manualmente e apontar nos arquivos de parâmetro, como o pai do GoldenGate (Carbonera) me indicou, uma das novidades dessa versão é a presença de scripts que fazem esse download de forma automática.
Sendo assim, depois da VM criada, você precisa acessa-la via SSH e dentro do diretório /u01/app/ogg/opt/DependencyDownloader/ e executar o script kafka.sh passando a versão desejada :
-bash-4.2$ ./kafka.sh 3.1.0
Caso queira ver as versões disponíveis basta entrar nesse link: https://search.maven.org/artifact/org.apache.kafka/kafka-clients
É importante anotar o diretório onde o download foi feito (caso você altere o padrão) pois precisamos aponta-lo em nossa configuração.
Replicat
O nosso replicat é dividido em 3 arquivos, um que é o replicat propriamente dito, um que parametriza o Kafka e outro com as credenciais, aqui tentei manter todos com o nome bem parecido, a configuração pode ser feita via interface gráfica (no Receiver Service) ou criando os arquivos manualmente:
oss.prm
REPLICAT oss TARGETDB LIBFILE libggjava.so SET property=/u02/deployments/Marketplace/etc/conf/ogg/OSS.properties MAP ORCL19_PDB1.HR.*, TARGET *.*;
Perceba que no .prm apontamos um arquivo de propriedades que contém a parametrização do Kafka:
OSS.properties
# Properties file for Replicat oss
#Kafka Handler Template
gg.handlerlist=kafkahandler
gg.handler.kafkahandler.type=kafka
#TODO: Set the name of the Kafka producer properties file.
gg.handler.kafkahandler.kafkaProducerConfigFile=oss_producer.properties
#TODO: Set the template for resolving the topic name.
gg.handler.kafkahandler.topicMappingTemplate=${fullyQualifiedTableName}
gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys}
gg.handler.kafkahandler.mode=op
gg.handler.kafkahandler.format=json
gg.handler.kafkahandler.format.metaColumnsTemplate=${objectname[table]},${optype[op_type]},${timestamp[op_ts]},${currenttimestamp[current_ts]},${position[pos]}
#TODO: Set the location of the Kafka client libraries.
gg.classpath=dirprm/:/u01/app/ogg/opt/DependencyDownloader/dependencies/kafka_3.1.0/*
jvm.bootoptions=-Xmx512m -Xms32m
Aqui precisamos ajustar três parametros:
- gg.handler.kafkahandler.kafkaProducerConfigFile = arquivo com as credenciais do OSS
- gg.handler.kafkahandler.topicMappingTemplate = Como ele vai criar/identificar os tópicos
- gg.classpath = Localização das bibliotecas que fizemos o download com o kafka.sh
Os outros parâmetros controlam coisas como formato de escrita, quais colunas vão ser escritas e por ai vai, caso queira customizar alguma coisa, aqui: https://docs.oracle.com/en/middleware/goldengate/big-data/21.1/gadbd/using-kafka-handler.html#GUID-E43DB743-4A2A-4C2F-97E8-50BB22CACCE3 você tem a documentação deles.
Agora precisamos montar nosso arquivo de credenciais com os dados que pegamos lá no Stream Pool, um ponto importante é que o seu password é um Auth Token que pode ser gerado na página de gerenciamento seu usuário do lado esquerdo, lembre de copia-lo para um lugar seguro pois ele só é exibido na criação do Token.
oss_producer.properties
bootstrap.servers=cell-1.streaming.us-ashburn-1.oci.oraclecloud.com:9092 security.protocol=SASL_SSL sasl.mechanism=PLAIN value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="bXXXXX" password="XXXX";
Testando
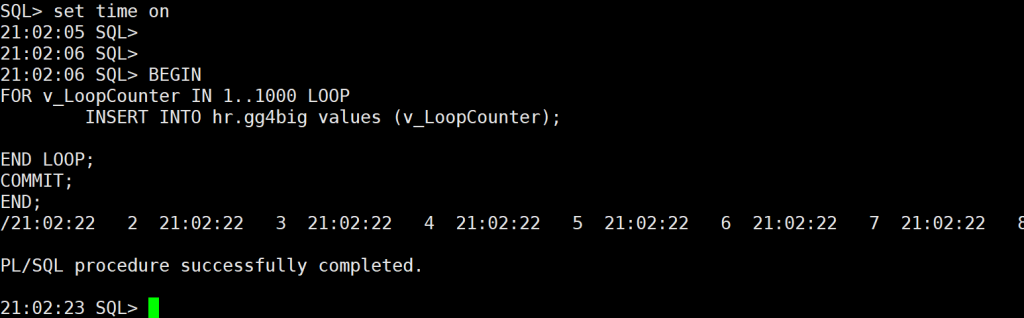
Insert na tabela HR.GG4BIG:
Mensagens no OSS
Como marcamos a opção de criação automática de tópicos, o replicat já consegue criar sozinho:

E já podemos ver nossas mensagens(que nesse caso foi o insert) chegando:
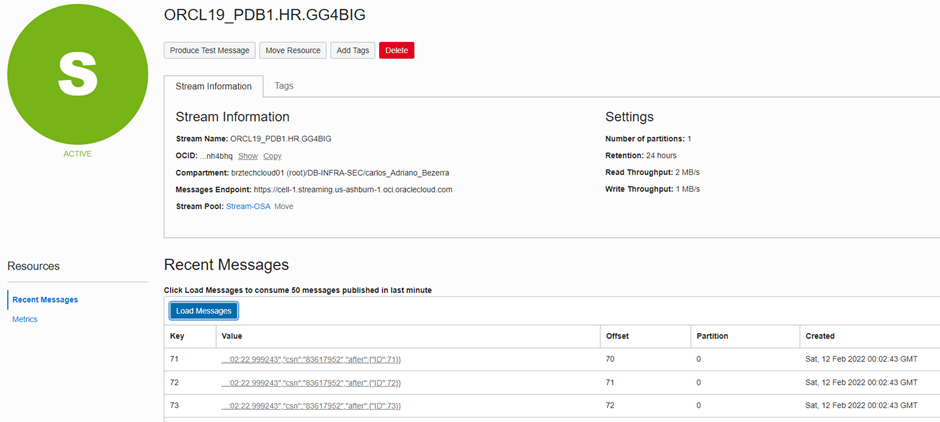
Exemplo de mensagem
{"op_type":"I","op_ts":"2022-02-12 01:30:44.003338","csn":"83673974","after":{"ID":84}}
Nela temos o tipo de operação (I), e o valor, caso façamos um update:
{"op_type":"U","op_ts":"2022-02-12 01:33:25.015390","csn":"83677632","before":{"ID":93},"after":{"ID":1}}
Temos o tipo U com o valor anterior e o novo, tudo isso pode ser controlado pelo parâmetro gg.handler.kafkahandler.format.metaColumnsTemplate