These days, automation is a no-brainer when working with cloud environments. Following best practices can really speed things up and get your product to market faster. In this post, I’ll show you how to use Terraform, REST API, and OCI DevOps to build a CI/CD pipeline. I’ll cover the basics of each tool, so you’ll have a solid starting point. Got questions? Drop them in the comments—I’m here to help!
Terraform is a powerful tool for deploying infrastructure as code, and I’ve relied on it for a long time to automate and manage my infrastructure efficiently. One key thing to understand is that Oracle provides a Terraform provider—a piece of code that allows Terraform to integrate with Oracle’s services. Additionally, there are specific resources to support OCI GoldenGate, which translates Terraform configurations into OCI resources.
One important best practice is to store your variables in a dedicated file to avoid hardcoding values in your code. This approach keeps your configurations clean and flexible. Here’s an example of my tf.vars file (and don’t forget to load it before running your code!):
export TF_VAR_region=YOUR_REGION
export TF_VAR_tenancy_ocid=YOUR_TENANCY_OCID
export TF_VAR_user_ocid=YOUR_USER_OCID
export TF_VAR_private_key_path=YOUR_PEM_FILE
export TF_VAR_fingerprint=XXXXX
export TF_VAR_compartment_ocid=YOUR_COMPARTMENT_OCIDAnd my provider.tf file (the file that tells terraform that we are working with OCI):
provider "oci" {
region = var.region
}
variable "tenancy_ocid" {}
variable "region" {}
variable "compartment_ocid" {}OCI GoldenGate Terraform Resources
Using Terraform is like building with Lego—you need all the pieces in place to make it work. In this case, our building blocks are:
- oci_golden_gate_deployment This resource is used to create deployments, which include components like the subnet and OCPU quantity. It also manages the lifecycle of your deployment, including starting, stopping, and scaling.
- oci_golden_gate_connection This resource handles connections for your GoldenGate deployment.
- oci_golden_gate_connection_assignment This resource assigns connections to your deployment. Connections can be shared across multiple deployments, allowing you to reuse the same object efficiently.
Deployment Resource (oci_golden_gate_deployment)
When working with Terraform files, I prefer to describe resource parameters using a list object. This approach makes the code more reusable and easier to manage. Here’s how I structure the required information for deployment:
variable "deployment_list" {
type = list(object({
deployment_name = string
deployment_subnet = string
deployment_type = string
deployment_ocpu = number
deployment_autoscaling = bool
#deployment_compartment = string
deployment_description = string
deployment_tech = string
deployment_user = string
deployment_password_secret_id = string
deployment_status = string
}))
default = [{ deployment_name = "ORCL",
deployment_subnet = "ocid1.subnet.oc1.xxxxxxx",
deployment_type = "DEVELOPMENT_OR_TESTING",
deployment_tech = "DATABASE_ORACLE",
deployment_ocpu = 2,
deployment_autoscaling = true,
deployment_description = "abc123",
deployment_user = "oggadmin",
deployment_password_secret_id = "ocid1.vaultsecret.oc1.xxxxxx",
deployment_status = "ACTIVE" },
{ deployment_name = "BIGDATA",
deployment_subnet = "ocid1.subnet.oc1.xxxxxx",
deployment_type = "DEVELOPMENT_OR_TESTING",
deployment_tech = "BIGDATA",
deployment_ocpu = 2,
deployment_autoscaling = true,
deployment_description = "abc123",
deployment_user = "oggadmin",
deployment_password_secret_id = "ocid1.vaultsecret.oc1.xxxxxxxxx",
deployment_status = "ACTIVE" }
]
}And I create a loop over that variable:
resource "oci_golden_gate_deployment" "ogg_deployments" {
#Required
for_each = { for d in var.deployment_list : d.deployment_name => d }
compartment_id = var.compartment_ocid #var.compartment_id
cpu_core_count = each.value.deployment_ocpu
deployment_type = each.value.deployment_tech #PRODUCTION,DEVELOPMENT_OR_TESTING
display_name = each.key
is_auto_scaling_enabled = each.value.deployment_autoscaling
license_model = "BRING_YOUR_OWN_LICENSE" #BYOL=BRING_YOUR_OWN_LICENSE INCLUDE=LICENSE_INCLUDED
subnet_id = each.value.deployment_subnet
description = each.value.deployment_description
environment_type = each.value.deployment_type
is_public = false
ogg_data {
#Required
deployment_name = each.value.deployment_name
#Optional
#admin_password = each.value.deployment_password
admin_username = each.value.deployment_user
#ogg_version = var.deployment_ogg_data_ogg_version
password_secret_id = each.value.deployment_password_secret_id
}
state = each.value.deployment_status
}oci_golden_gate_connection (deploymentConnection.tf)
Although the resources are independent, for this code to work, you must first create the deployments—or run everything together. This is because some details are retrieved from the deployment.
Below is the familiar resource object:
variable "connection_list" {
type = list(object({
connection_name = string
connection_subnet = string
technology_type = string
routing_method = string
}))
default = [{ connection_name = "orcl", connection_subnet = "ocid1.subnet.oc1.uk-london-1.xxxxxxx", technology_type = "GOLDENGATE", routing_method = "DEDICATED_ENDPOINT" }]
}
resource "oci_golden_gate_connection" "ogg_deployment_connection" {
for_each = { for d in oci_golden_gate_deployment.ogg_deployments : d.display_name => d }
#Required
compartment_id = var.compartment_ocid
connection_type = "GOLDENGATE"
display_name = "conn_${each.key}"
technology_type = "GOLDENGATE"
description = "ttt"
host = each.value.fqdn
private_ip = each.value.private_ip_address
port = 443
subnet_id = each.value.subnet_id
routing_method = "DEDICATED_ENDPOINT"
trigger_refresh = true
}The key element here is the for_each loop, which iterates through each created deployment to create a connection for it. It’s crucial that both the connection_type and technology_type are set to GOLDENGATE for proper functionality.
oci_golden_gate_connection(createConnection.tf)
variable "connection_list_targets" {
type = list(object({
connection_name = string
connection_subnet = string
technology_type = string
routing_method = string
target_ip = string
fqdn = string
target_port = number
connection_type = string
}))
default = [{ connection_name = "orcl_src", connection_subnet = "ocid1.subnet.oc1.uk-london-1.xxxxx", connection_type = "ORACLE", technology_type = "ORACLE_DATABASE", routing_method = "DEDICATED_ENDPOINT", target_ip = "172.19.1.95", fqdn = "meudb.com.br", target_port = 1521 }]
}
resource "oci_golden_gate_connection" "ogg_connection" {
for_each = { for d in var.connection_list_targets : d.connection_name => d }
compartment_id = var.compartment_ocid
connection_type = each.value.connection_type
display_name = "conn_${each.key}"
technology_type = each.value.technology_type
username = "system"
password = "XXXXXX"
connection_string = "${each.value.fqdn}:${each.value.target_port}"
description = "ttt"
host = each.value.fqdn
private_ip = each.value.target_ip
port = each.value.target_port
subnet_id = each.value.connection_subnet
routing_method = "DEDICATED_ENDPOINT"
trigger_refresh = true
}This script will create a connection to a Oracle Database (connection_type=”ORACLE”) using a dedicated endpoint(routing_method=”DEDICATED_ENDPOINT), see that we are using an object to hold the information and its easy to update/adjust according to your requirements.
Connection Assignement (assignConnection.tf)
variable "assign_conn" {
type = list(object({
connection_id = string
deployment_target = string
}))
default = [{ connection_id = "ocid1.goldengateconnection.oc1.uk-london-1.xxxxx",
deployment_target = "ocid1.goldengatedeployment.oc1.uk-london-1.xxxxx" },
{ connection_id = "ocid1.goldengateconnection.oc1.uk-london-1.xxx",
deployment_target = "ocid1.goldengatedeployment.oc1.uk-london-1.xxx" }
]
}
resource "oci_golden_gate_connection_assignment" "connection_assignment" {
for_each = { for c in var.assign_conn : c.connection_id => c }
#Required
connection_id = each.value.connection_id
deployment_id = each.value.deployment_target
}This code will assign a connection(connection_id) to a deployment(deployment_target).
Now that our infrastructure is (hopefully) deployed and running, we can move on to deploying and managing GoldenGate processes.
To get a better grasp of how this works, I recommend checking out the official documentation: https://docs.oracle.com/en/middleware/goldengate/core/23/oggra/index.html
There, you’ll find essential information such as:
- How to authenticate with the GoldenGate API
- Endpoints for various operations
- Operations and examples for each GoldenGate endpoint/process
Important Note: For OCI GoldenGate, be sure to append /adminsrvr to some endpoints.
| GoldenGate | OCI GoldenGate |
| /services/v2/logs | /services/adminsrvr/v2/logs |
| /services/v2/installation/services | /services/adminsrvr/v2/installation/services |
When it comes to authenticating with OCI GoldenGate, you have a few options. In this example, I’ll use a username and password for simplicity, but tokens are also a viable alternative.
You can run a curl command:
[tanaka@ ~]$ curl -k -u USER:PASSWORD -X GET https://SERVICE_ENDPOINT/services/adminsrvr/v2/logs | jq -r
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2250 100 2250 0 0 2416 0 --:--:-- --:--:-- --:--:-- 2414
{
"$schema": "api:standardResponse",
"links": [
{
"rel": "canonical",
"href": "https://SERVICE_ENDPOINT/services/adminsrvr/v2/logs",
"mediaType": "application/json"
},
{
"rel": "self",
"href": "https://SERVICE_ENDPOINT/services/adminsrvr/v2/logs",
"mediaType": "application/json"
},
{
"rel": "describedby",
"href": "https://SERVICE_ENDPOINT/services/adminsrvr/v2/metadata-catalog/logs",
"mediaType": "application/schema+json"
}
],
...But our goal here is to implement a CI/CD pipeline, so I wrote a very simple python script that runs some commands based in conditions (more latter), here I’m using the requests library.
import requests
import json
import os
from requests.auth import HTTPBasicAuth
import tarfile
import subprocess
import sys
deploymentUrl='SERVICE_ENDPOINT'
deploymentUser='USERNAME'
deploymentPasswd='PASSWORD'
b_auth = HTTPBasicAuth(deploymentUser,deploymentPasswd)
# r = requests.get('https://'+deploymentUrl+'/services/v2/logs/restapi', auth=b_auth,verify=False)
# response = r.text
# print(response)
def createCredential():
headers = {'Content-type': 'application/json', 'Accept':'application/json'}
with open('credential.json') as f:
d=json.load(f)
print(d)
r = requests.post('https://'+deploymentUrl+'/services/v2/credentials/OracleGoldenGate/con0122', auth=b_auth,verify=False,headers=headers, data=json.dumps(d))
response = r.json()
print(response)
def createExtract(exName,prmFile):
print('Creating Extract.....')
headers = {'Content-type': 'application/json', 'Accept':'application/json'}
with open(prmFile) as f:
d=json.load(f)
print(d)
r = requests.post('https://'+deploymentUrl+'/services/v2/extracts/'+exName, auth=b_auth,verify=False,headers=headers, data=json.dumps(d),timeout=5)
response = r.json()
print(response)
if r.status_code==200:
print('OK')
else:
print('Failed to run')
print(response)
#response = r.headers
# print(response)
def updateExtract(exName,prmFile):
print('Updating Extract.....')
headers = {'Content-type': 'application/json', 'Accept':'application/json'}
with open(prmFile) as f:
d=json.load(f)
print(d)
r = requests.patch('https://'+deploymentUrl+'/services/v2/extracts/'+exName, auth=b_auth,verify=False,headers=headers, data=json.dumps(d),timeout=5)
response = r.json()
print(response)
if r.status_code==200:
print('OK')
else:
print('Failed to run')
print(response)
#createExtract()
#if __name__ == '__main__':
# globals()[sys.argv[1]]()
# print('Creating Credentials.....')
# createCredential()
# print('Creating Extract.....')
# createExtract()
if __name__ == '__main__':
args = sys.argv
globals()[sys.argv[1]](*args[2:])And you can call it passing parameters like this:
python3 main.py createExtract EX1 extractESRC.jsonWhere extractESRC.json is a Json file with this content:
{"description": "criar ex",
"credentials": {
"domain": "OracleGoldenGate",
"alias": "con012"
},
"intent": "Unidirectional",
"status": "stopped",
"begin": "now",
"managedProcessSettings": "Default",
"encryptionProfile": "LocalWallet",
"source": "tranlogs",
"registration": {
"share": true
},
"targets": [
{
"name": "ee",
"remote": false,
"path": "ESRC",
"sequence": 0,
"sizeMB": 500,
"offset": 0
}
],
"config": [
"EXTRACT ESRC",
"USERIDALIAS con012 DOMAIN OracleGoldenGate",
"EXTTRAIL ESRC/ee",
"TRANLOGOPTIONS SOURCE_OS_TIMEZONE GMT-3",
"table dbworld.*;"
] }Or python3 main.py createCredential cred2 to create a credential with these parametes:
{
"userid":"tanaka@192.168.56.1:1521/dbsrc",
"password":"abc123"
}OCI DevOps
This part is heavily based on this article by Deepak Devadathan https://medium.com/@xsgdkh/infrastructure-provisioning-using-oci-devops-resource-manager-1e8a74d02a70 , so go there to read in details, and I can’t forget to thanks Jose Neto that helped me with GitHub integration.
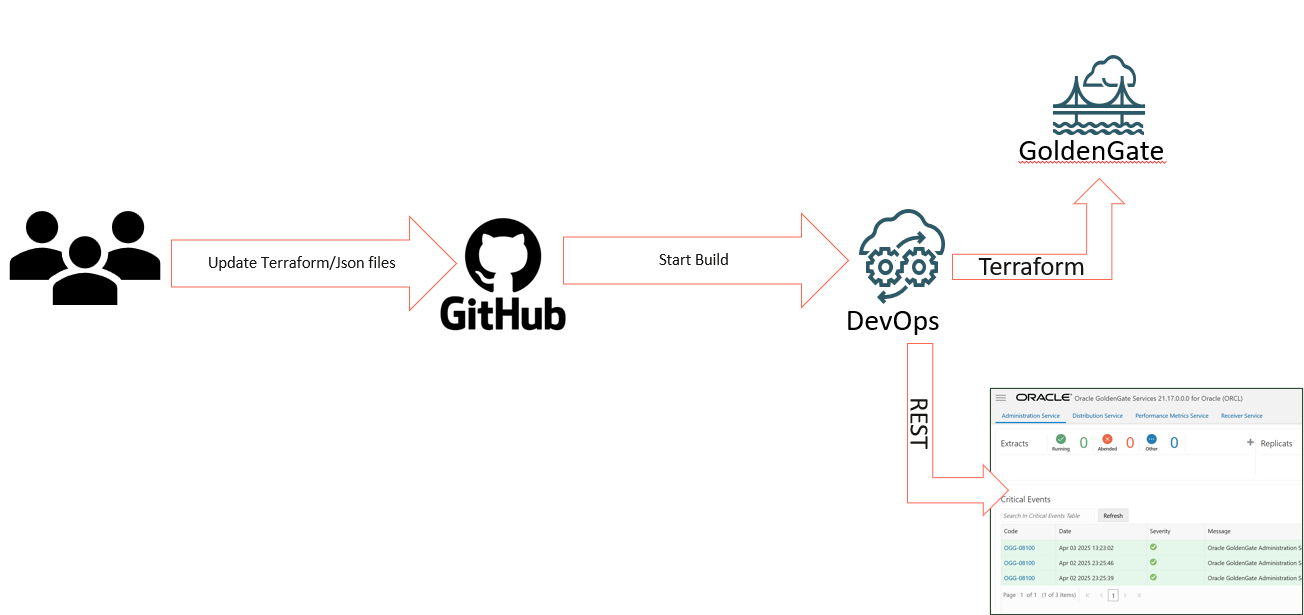
My idea here is to have two pipelines that monitors my private repository, if I update and commit a file it will trigger the infrastructure pipeline, if the commit is in another file(ogg-api/build_spec.yaml) it will trigger a REST API call, here is the workflow:
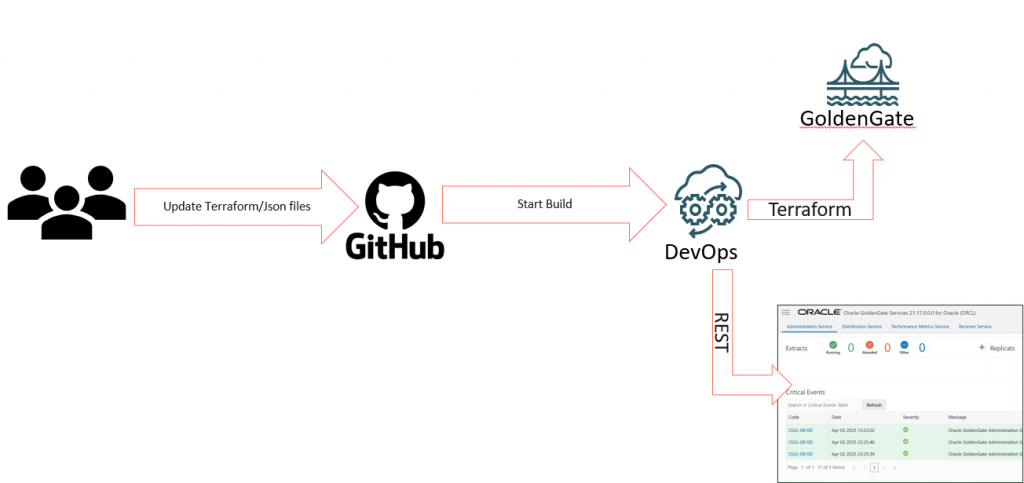
GitHub Configuration
First, we need to setup a token in our GitHub, to do that, follow these steps:
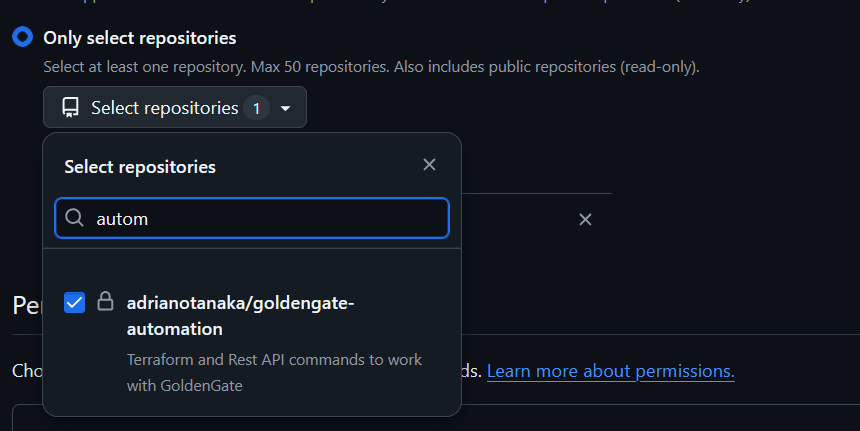
And create a (software) Secret in your OCI Vault using this Token:
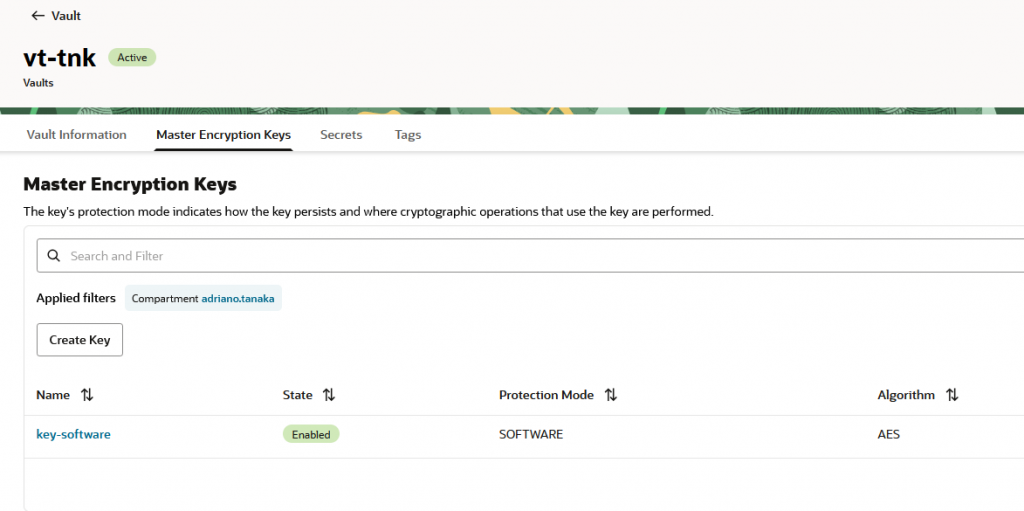
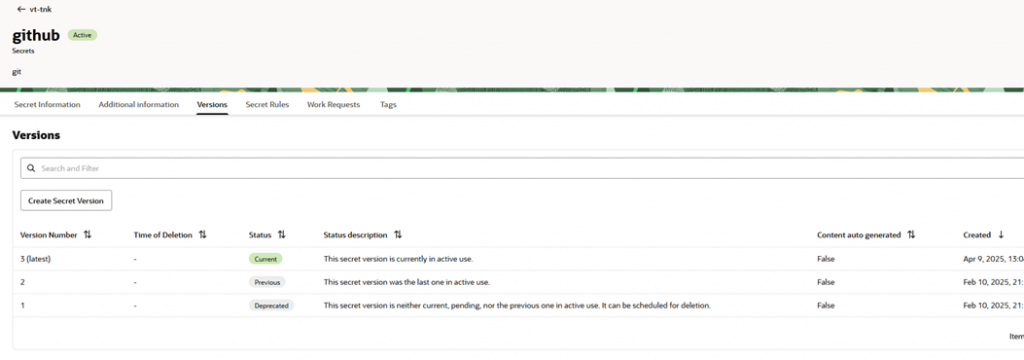
We will use it to sync GitHub and OCI Code Repository.
OCI DevOps
Create a Connection under your DevOps project:
External Connection > Create External Connection:
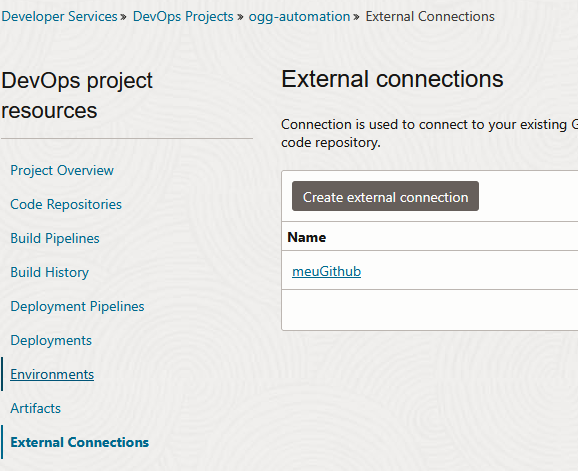
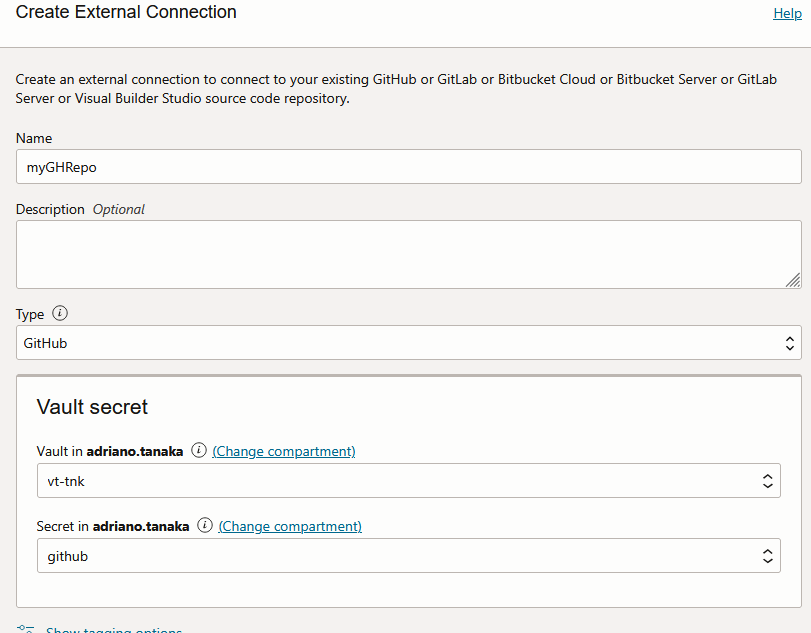
And validate your connection:
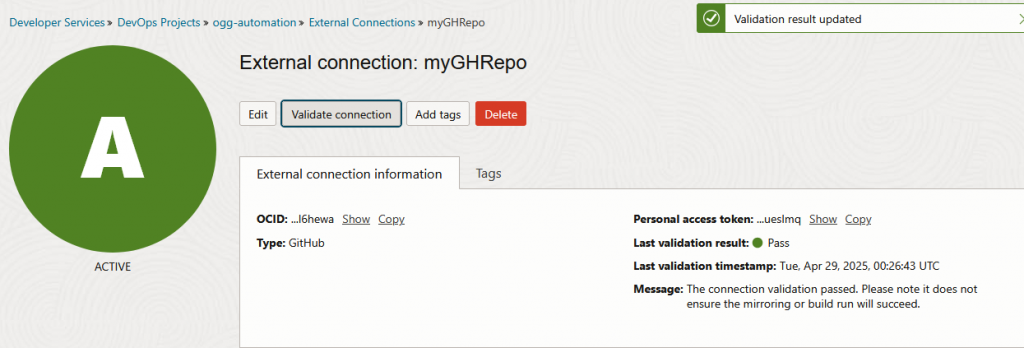
Go back to your DevOps project > Code Repositories > Mirror Repository and choose the external connection and your repository:
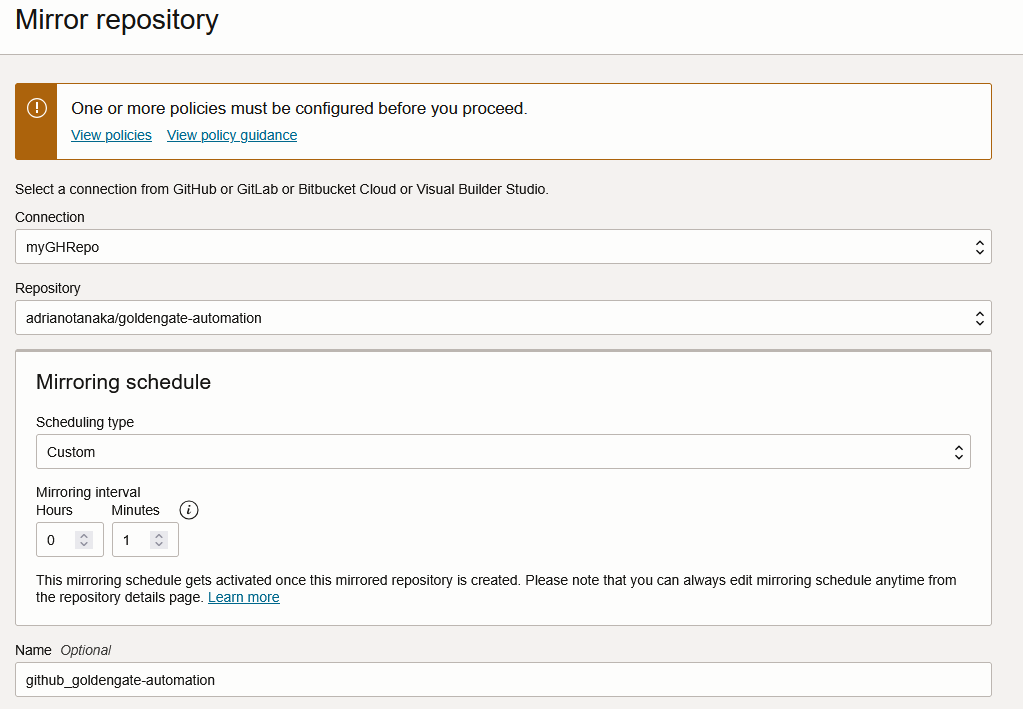
And wait for the first sync, you should be able to see the commits and files:
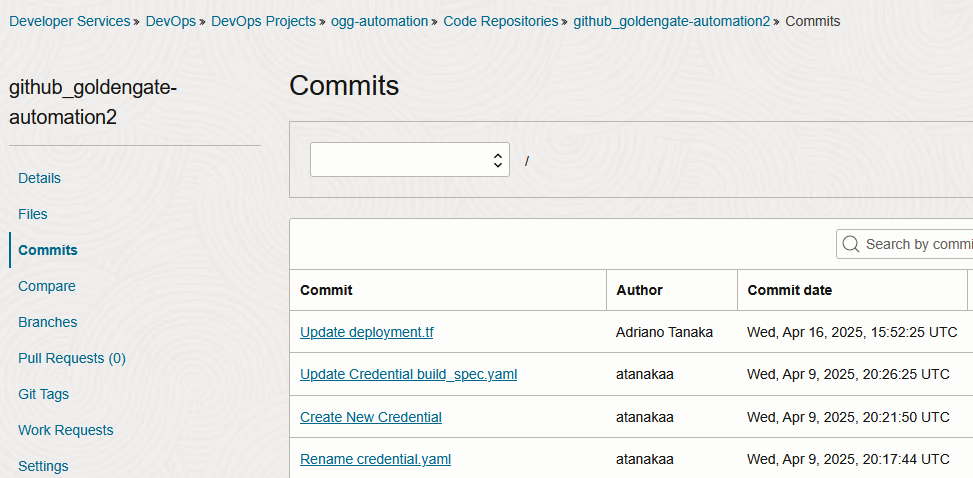
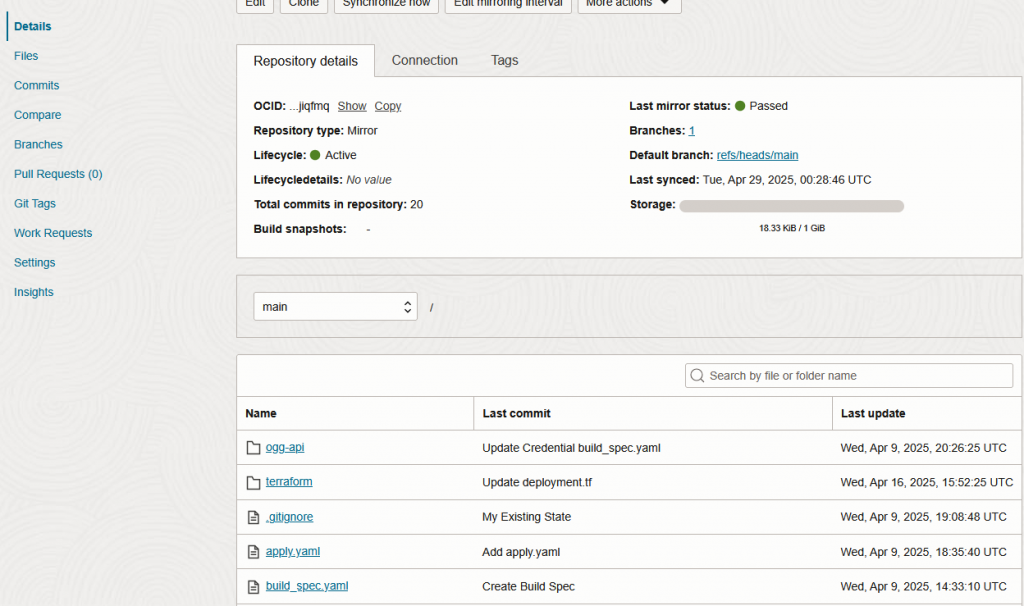
It’s important to follow the Deepak Devadathan article before creating the next step.
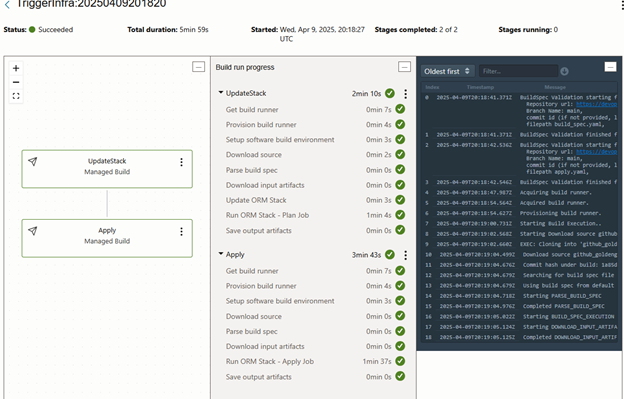
Here I have an UpdateStack and a Apply step inside a Build Pipeline called InfraDeployment:
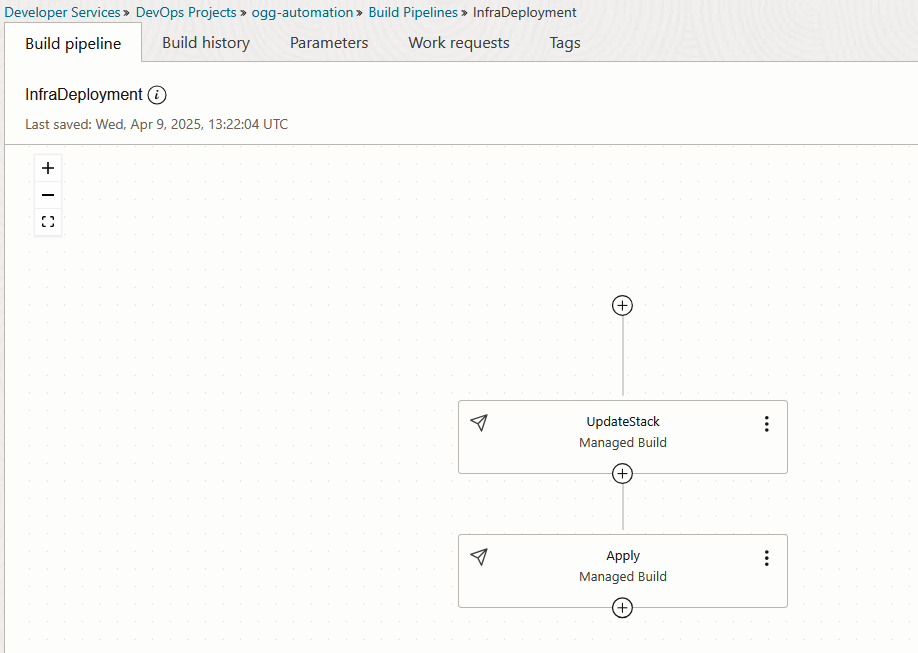
And a Pipeline called ProcessDeployment that will call GoldenGate APIs:
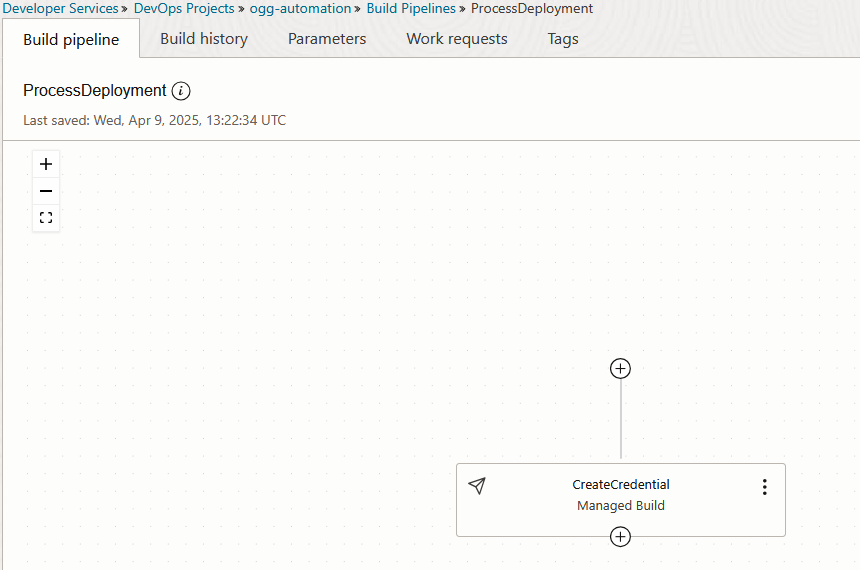
Under your DevOps project, go to Triggers, so we will create the logic of pipeline trigger based on file commit.
Choose a name and the Source must be GitHub(remember to choose your credential), and your action will be the InfraDeployment pipeline.
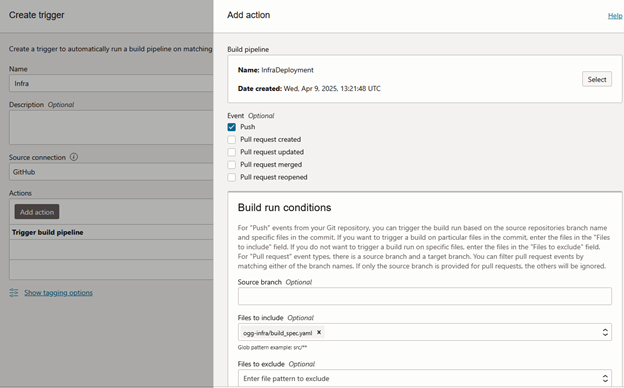
I just want this pipeline running when I commit to ogg-api/credential.yaml, so I put this name under Files to Include field, important: copy the Trigger URL and Secret, because it will be shown just once, and we will need this information to configure a WebHook in GitHub.
Here my ogg-api/credential.yaml file:
version: 0.1
component: build
timeoutInSeconds: 6000
runAs: root
shell: bash
env:
variables:
deploymentUrl: "DEPLOYMENT_ENDPOINT"
deploymentUser: "USER"
deploymentPasswd: "PASSWORD"
exportedVariables:
- plan_job_id
- commit_hash_short
steps:
- type: Command
timeoutInSeconds: 1200
name: "Create Extract"
command: |
python3 main.py createCredential cred23
onFailure:
- type: Command
command: |
echo "Handling Failure"
echo "Failure successfully handled"
timeoutInSeconds: 40
runAs: rootGo to your GitHub repository > Settings > WebHooks and enter the captured information:
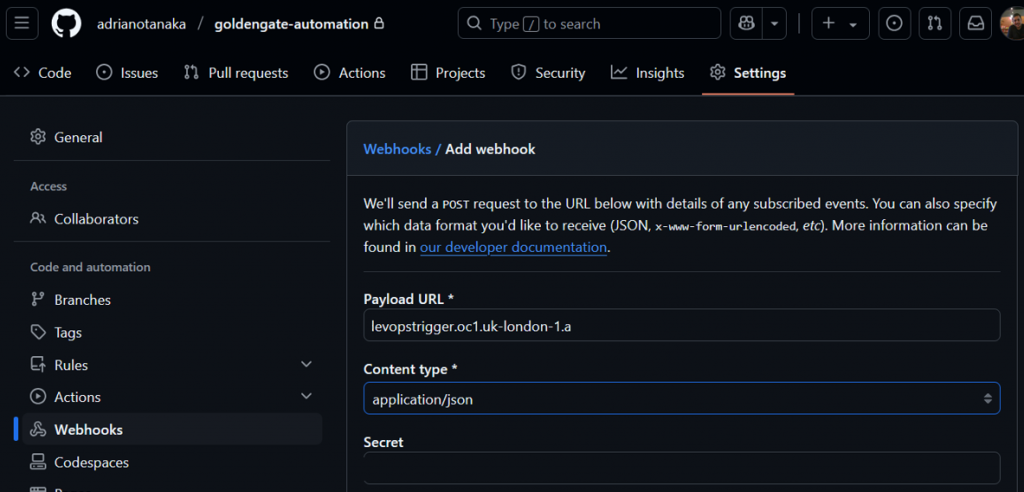
Repeat it to your Process pipeline but in Files to Include specify the ogg-api/credential.yaml
Testing
Ok, now we have everything in place and can test it, I will commit my terraform code to my GitHub, it will trigger our pipeline and get the code from OCI Code Repository: