
While preparing for the Oracle AI Vector Search Certified Professional Certification (1Z0-184-25), one of the most fascinating topics I encountered was Using Vector Embeddings, particularly with the new VECTOR DBMS/Packages. Here, I’ll share an example of how to load an ONNX model into your Oracle Database.
For reference, I’m running Oracle 23ai Free Edition and obtaining models from Hugging Face.
Converting an ONNX Model for Oracle Database
First, you cannot use ONNX models directly downloaded from Hugging Face. Before loading them into Oracle, you must convert them using OML4Py. Here’s a helpful tutorial on how to download and configure it: OML4Py Tutorial – Leveraging ONNX and Hugging Face for AI Vector Search.
Requirements for Conversion
To use OML4Py, ensure you have:
- Python and pip (version 3.12 or newer).
This is crucial, because if you attempt to load an ONNX model directly using DBMS_VECTOR.LOAD_ONNX_MODEL, you’ll likely encounter the following error:
ORA-54426: Tensor "input_ids" contains 2 batch dimensions.Converting and Exporting an ONNX Model in OML4Py
Within OML4Py, you can either:
- Use a preconfigured model from a provided list (ONNXPipelineConfig.show_preconfigured()).
- Download and customize a model manually (which I’ll demonstrate below).
Here’s the official Oracle documentation example, using ONNXPipeline and ONNXPipelineConfig (available from OML4Py v2.1):
from oml.utils import ONNXPipeline, ONNXPipelineConfig
config = ONNXPipelineConfig.from_template("text", max_seq_length=256,distance_metrics=["COSINE"], quantize_model=True)
pipeline = ONNXPipeline(model_name="thenlper/gte-small",config=config)
pipeline.export2file("testeModel22", output_dir=".")
To get the correct model_name, visit the Hugging Face model page and copy the name from the header.

Checking Model Size
Your ONNX model must be under 1GB, otherwise, the script will fail with a “Killed” status, to verify the size, check the Files tab on Hugging Face before downloading.
After a successful export, you should find an .onnx file in the specified `output_dir`:
-rwxrwxrwx 1 tanaka tanaka 87M your_preconfig_file_name.onnx
-rwxrwxrwx 1 tanaka tanaka 977K tok_your_preconfig_model_name2.onnx
-rwxrwxrwx 1 tanaka tanaka 977K tok_testeModel.onnx
-rwxrwxrwx 1 tanaka tanaka 4.9M tok_testeModel2.onnx
-rwxrwxrwx 1 tanaka tanaka 33M testeModel22.onnx
-rwxrwxrwx 1 tanaka tanaka 87M all-MiniLM-L6-v2.onnx
-rwxrwxrwx 1 tanaka tanaka 128M all_MiniLM_L12_v2.onnx
Files starting with tok_ are broken and cannot be used.
Importing the ONNX Model into Oracle Database
Now that the model is ready, follow these steps to import it into your Oracle Database:
- Create a user for model management.
- Create a Database Directory for model storage.
- Grant READ permission to the user for this directory.
- Import the model using DBMS_VECTOR.LOAD_ONNX_MODEL.
Example:
EXECUTE DBMS_VECTOR.LOAD_ONNX_MODEL('DM_DUMP', 'testeModel22.onnx', 'doc_model23334');Verifying Model Import with Oracle Tools
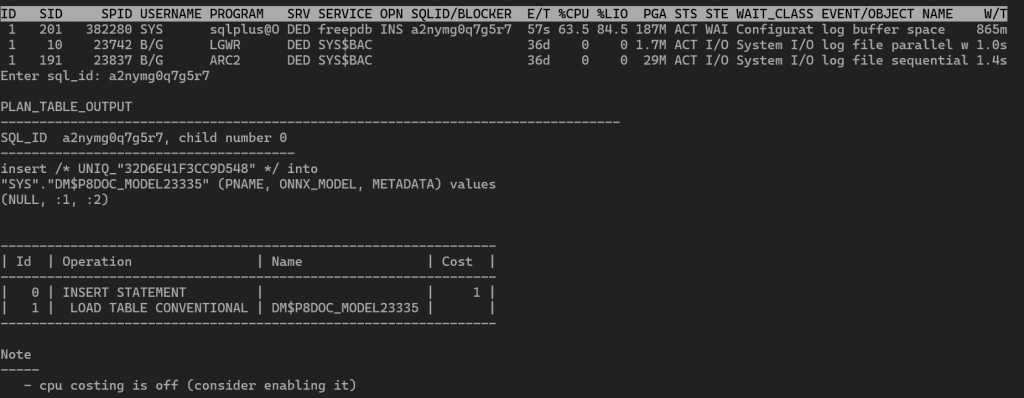
If you’re curious about the background process, use oratop to monitor commands executed behind the scenes.
The official Oracle documentation provides details on views created during this import process.


Using the Imported ONNX Model for Vector Embeddings/Search
Now that our model is inside the Oracle Database, let’s start embedding text vectors.
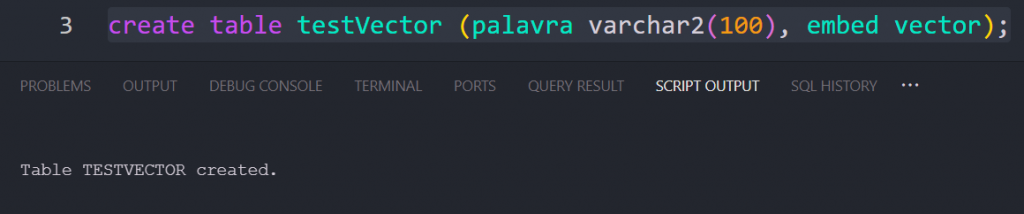
Create a Table for Embeddings
create table testVector (palavra varchar2(100), embed vector);
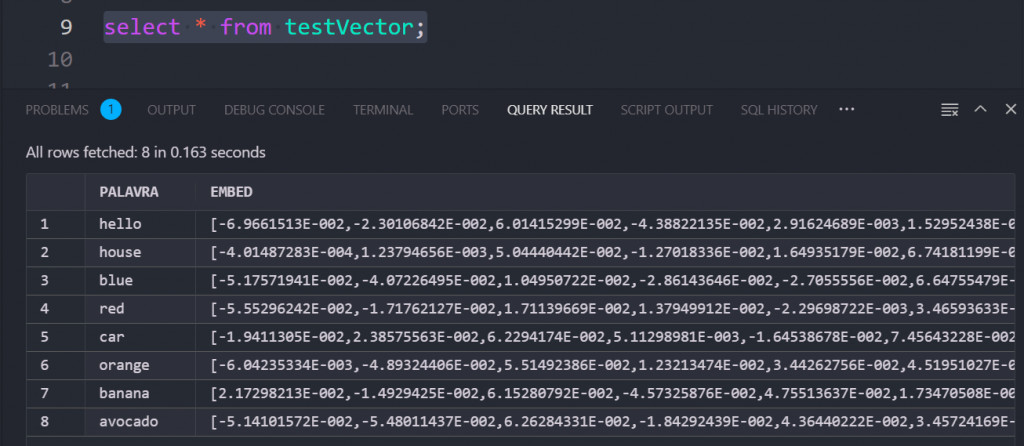
Inserting Data Using the Imported ONNX Model
insert into TESTVECTOR values ('hello',VECTOR_EMBEDDING(doc_model2333 USING 'hello' as DATA));
insert into TESTVECTOR values ('house',VECTOR_EMBEDDING(doc_model2333 USING 'house' as DATA));
insert into TESTVECTOR values ('blue',VECTOR_EMBEDDING(doc_model2333 USING 'blue' as DATA));
insert into TESTVECTOR values ('car',VECTOR_EMBEDDING(doc_model2333 USING 'car' as DATA));
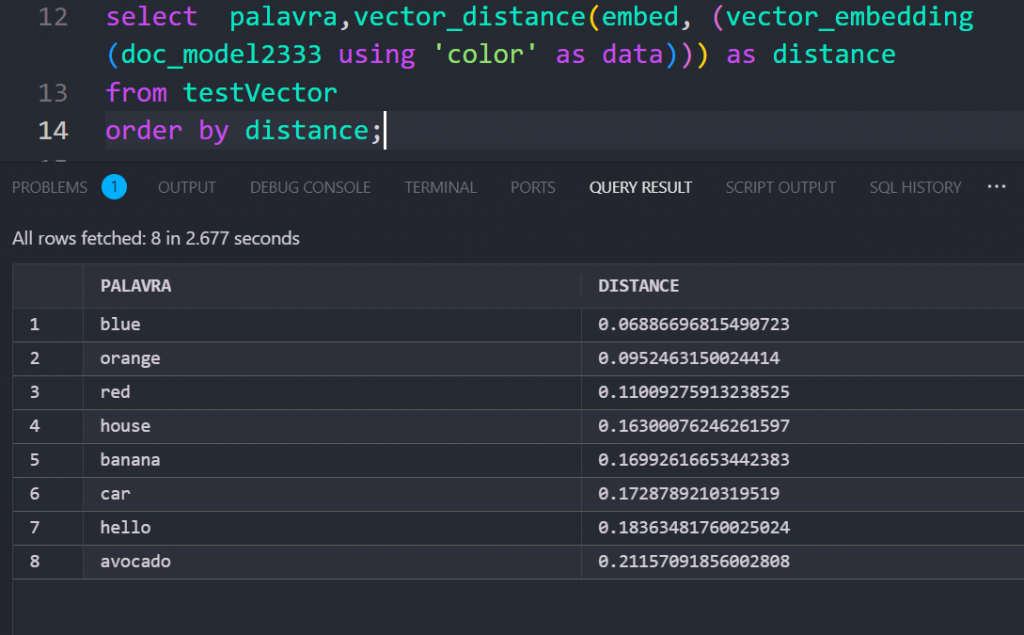
Retrieving Data Based on Vector Similarity
To query similar embeddings, use VECTOR_DISTANCE:
select palavra,vector_distance(embed, (vector_embedding(doc_model2333 using 'PUT_YOUR_WORD_HERE' as data))) as distance
from testVector
order by distance;
Lower distance = Higher similarity
For example, embedding “blue” may return results where “red,” “orange,” and “green” are more closely associated colors rather than random words.
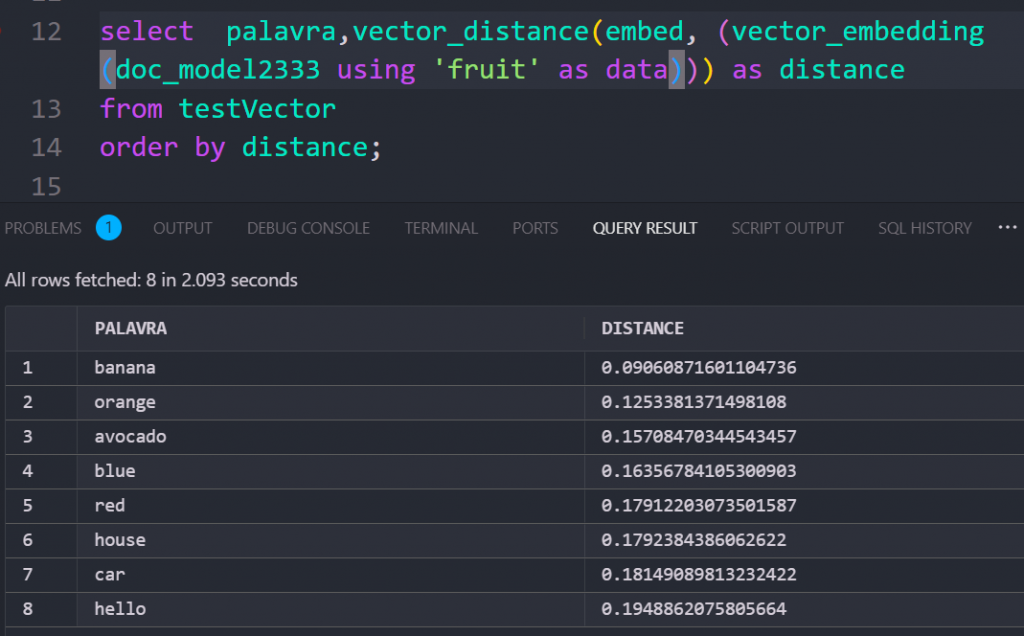
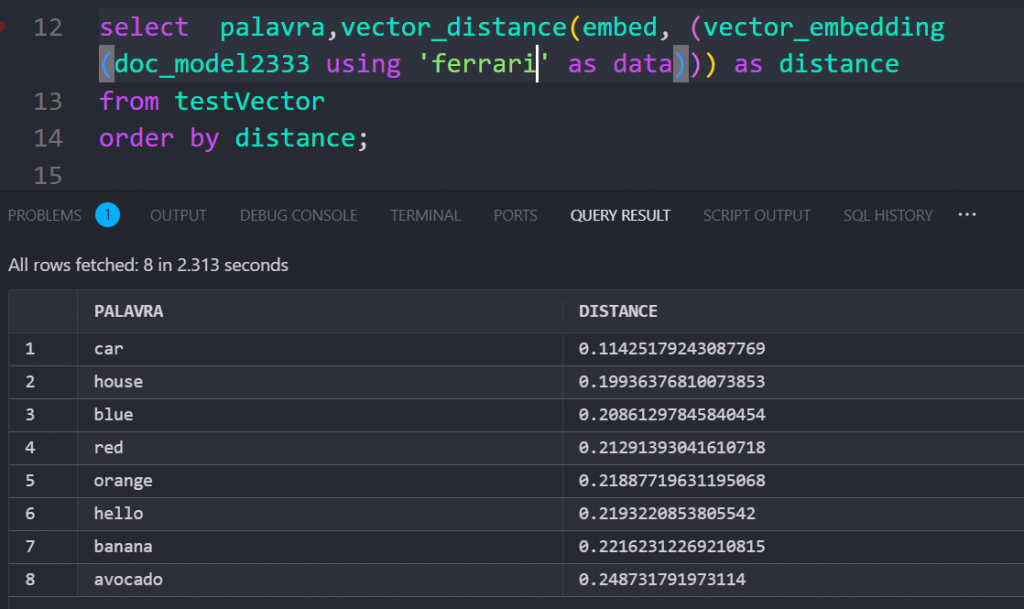
It’s crucial to consistently use the same model for both embedding and retrieving data to ensure accurate and meaningful results. This is the true power of embeddings—they grasp the meaning and semantics of your query, allowing your data to be efficiently structured and retrieved based on relevance rather than just exact matches.
Bonus Tip: Limiting Query Results
Use FETCH EXACT FIRST XXX ROWS to limit rows in your query output:
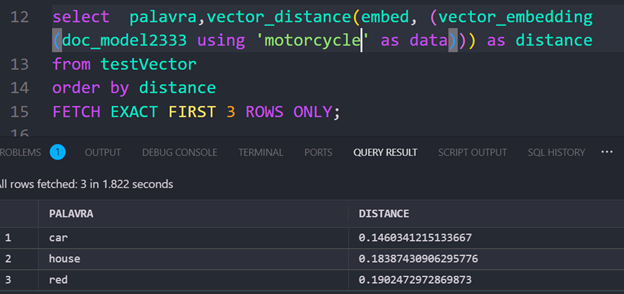
Hope this post will help you and if you have any question, feel free to get in touch or read the doc.
—