Nos meus outros posts sobre OCI Goldengate, falei sobre como configurar uma replicação entre um banco Oracle e o OSS/Kafka, nesse artigo vou demonstrar o procedimento para levar dados já existentes.
Caso queira mais detalhes você pode consultar esse artigo: GoldenGate Microservices Initial Load Instantiation with WebUI
Basicamente o que vamos fazer é:
- Criar um Extract Definitivo(Ext_hr)
- Criar um Extract do tipo Initial Load(INIHR)
- Configurar um receiver server a partir do OGG Bigdata lendo o trail do Extract do Initial Load
- Configurar um Distribution Service do OGG Oracle para o Bigdata enviando o Trail do Extract Definitivo
- Configurar (mas não iniciar) o Replicat Definitivo
- Configurar (e iniciar) o Replicat que lê o trail de initial Load
- Iniciar o Replicat Definitivo usando o parâmetro ATCSN
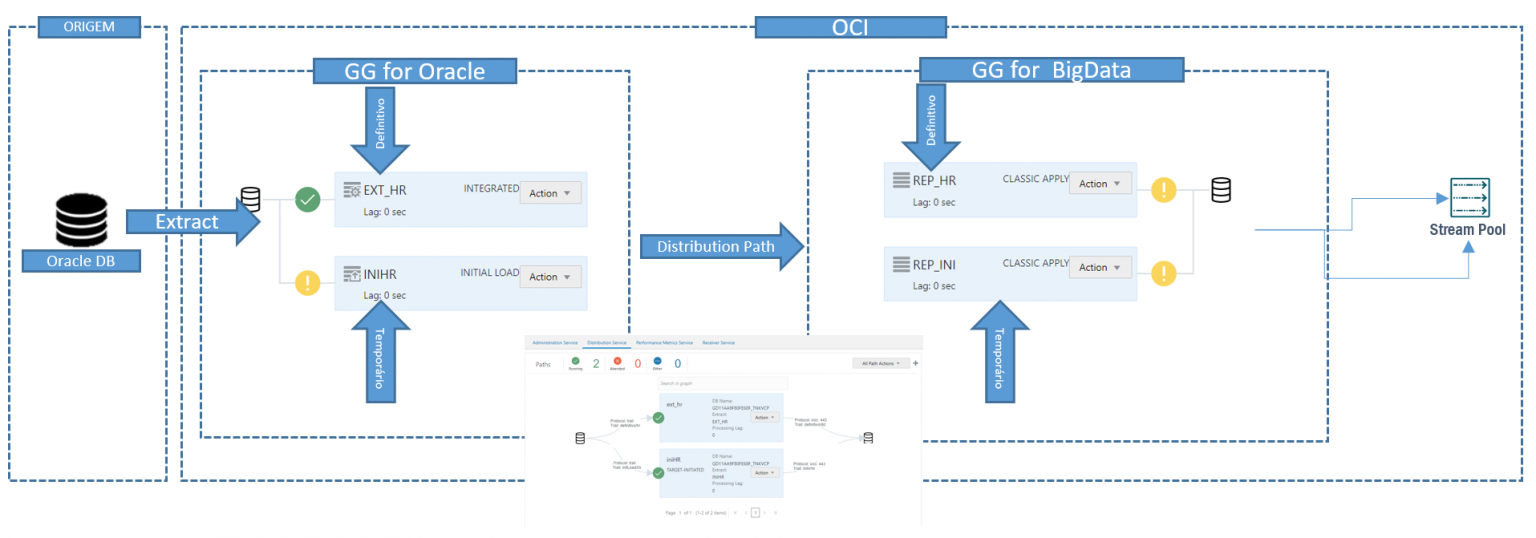
A nossa topologia vai ser a seguinte:
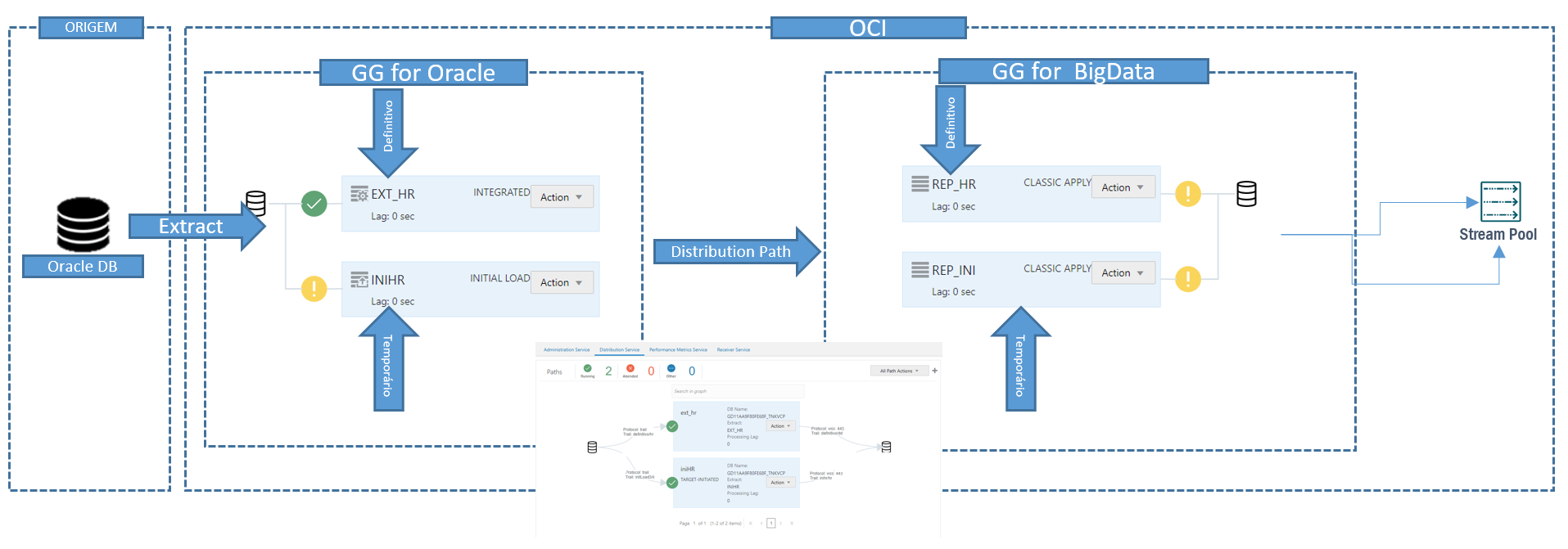
E vamos aproveitar a parte de credenciais desse outro tutorial aqui:
Mão na massa
O primeiro passo é criar e iniciar um Extract (EXT_HR) como já fizemos anteriormente nos outros artigos, depois disso vamos criar um Extract do tipo Initial Load(iniHR, código abaixo) é ele que vai ser o responsável por levar todos os dados e por isso nele colocamos o parâmetro SQLPREDICATE ‘AS OF SCN XXXXXX’;
EXTRACT iniHR USERIDALIAS atp_vcp DOMAIN OracleGoldenGate extfile initLoad3/ii megabytes 2000 purge TABLE TNK_SRC.*, SQLPREDICATE 'AS OF SCN 39083101740223';
Esse SCN deve ser capturado após o Extract normal (EXT_HR) ter sido iniciado e você pode usar o seguinte select:
SELECT to_char(current_scn) FROM V$DATABASE;
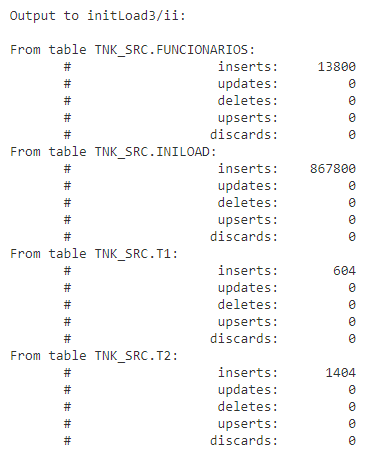
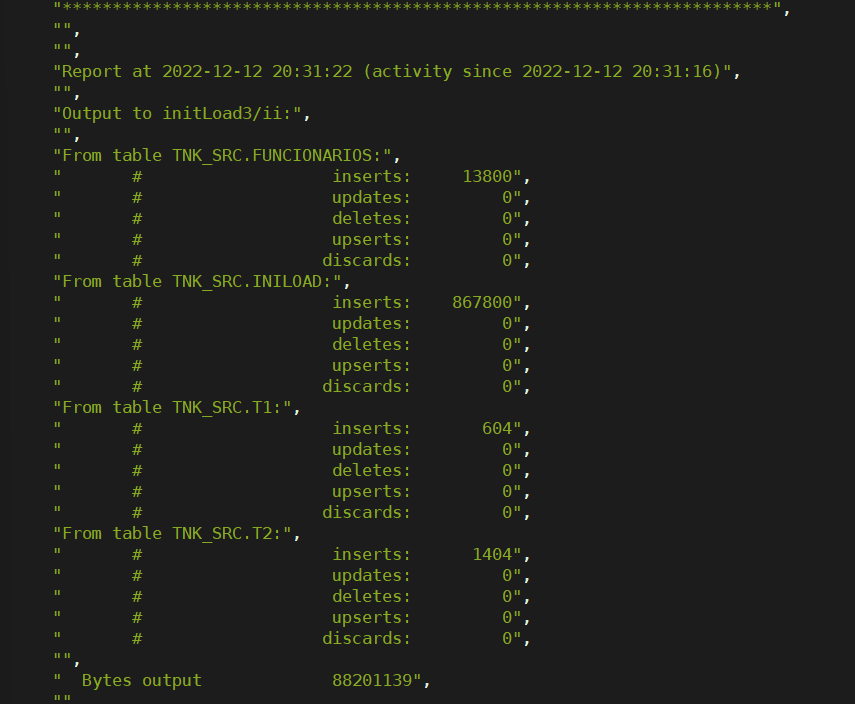
O Extract do tipo Initial load executa apenas uma vez e após a captura ele para sozinho ficando com o símbolo de exclamação amarelo, um resumo do que foi capturado por ser consultado na tela Report:
Ou se preferir fazer uma chamada de API:
curl -u oggadmin:"password" \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-H 'cache-control: no-cache' \
-X GET https://endpoint.oci.oraclecloud.com/services/adminsrvr/v2/extracts/SEUEXTRACT/info/reports/SEUEXTRACT.rpt | jq -r
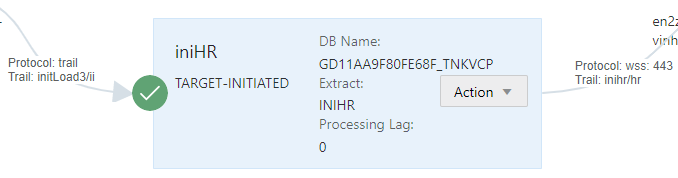
Receive Service
Depois que o Extract do tipo Initial Load terminar, você precisa ir no deploy do BigData e criar um receive service apontando para o trail do initial load, você precisa ter as credenciais criadas como mostrei aqui , no meu caso criei um receive chamado iniHR, lendo do trail initLoad3/ii(que está no deploy for oracle) e escrevendo no inihr/hr (que está no deploy big data).
O processo de criação também está descrito no artigo anterior.
Replicat Initial Load
Com o Receive Service criado, você já pode criar um replicat para o initial Load, esse processo deve ser feito no deploy do tipo BigData, basta criar o processo lendo o arquivo que o Receive Service está criando(no nosso caso o dest3/pp) e target como OSS, após criado, inicie a replicação, a mesma quantidade que foi extraída no Oracle deve aparecer na tela de estatísticas:
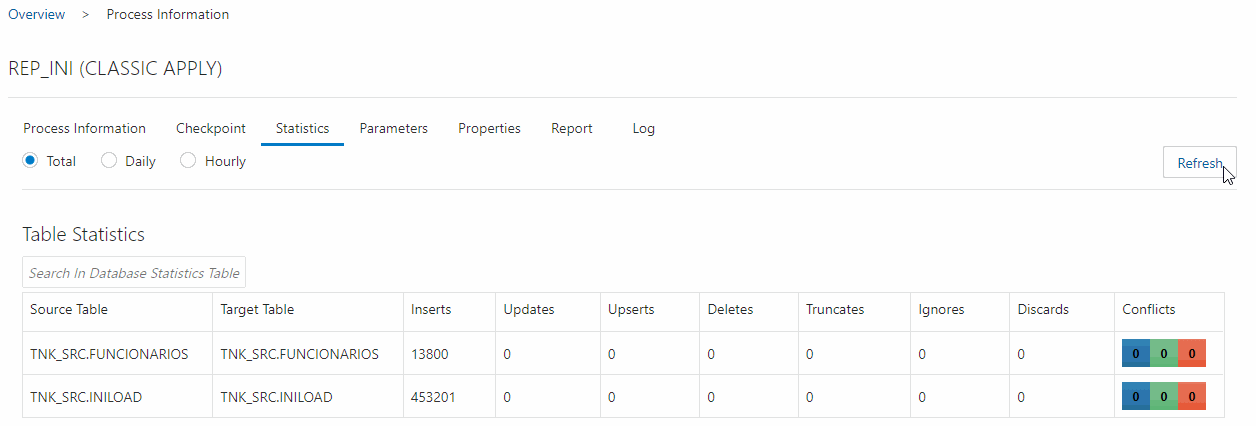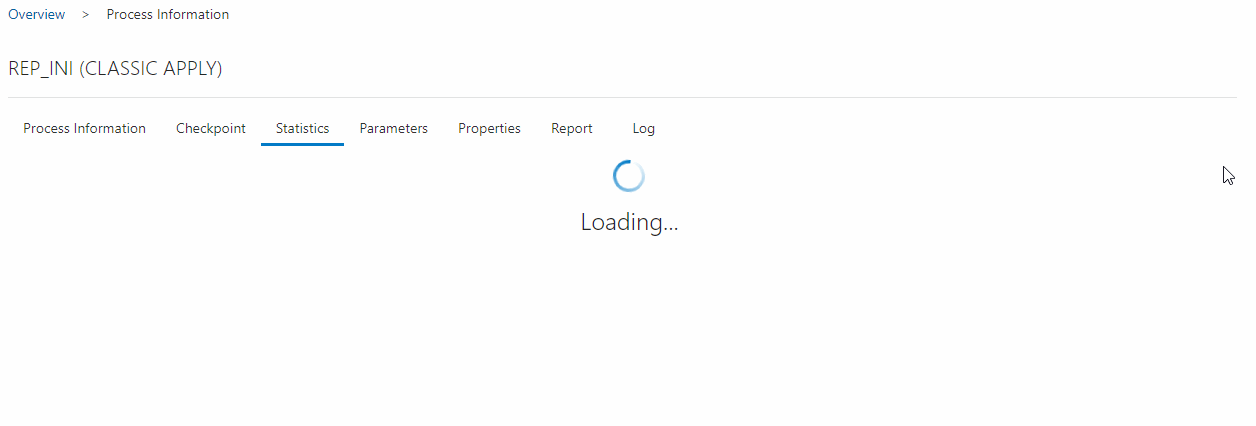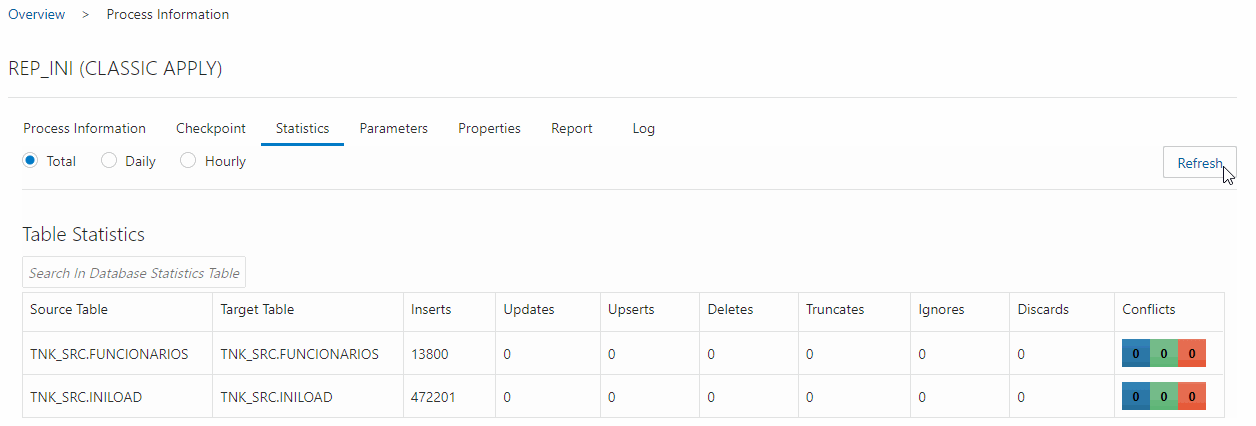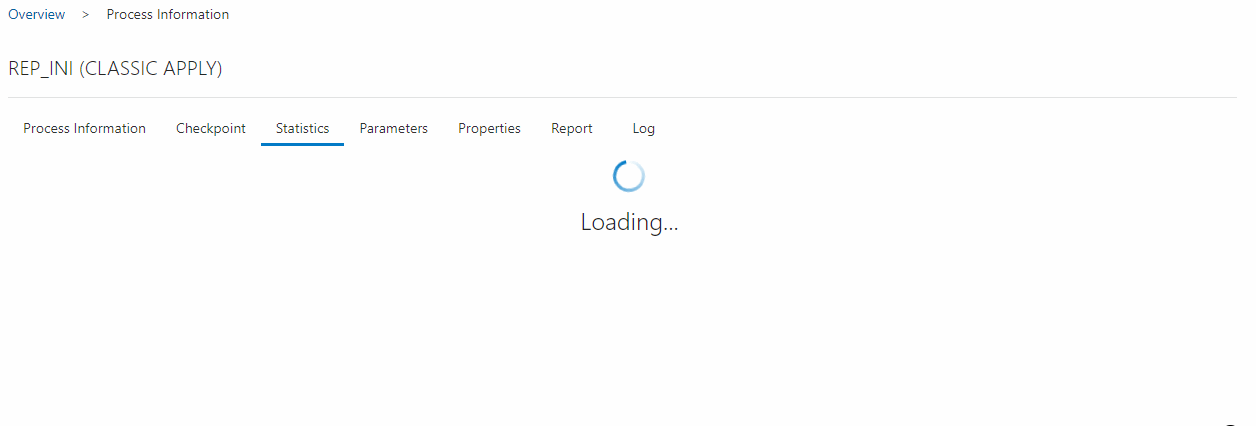
Depois que todas as linhas passarem pelo Replicat você deve apaga-lo.
Distribution Service
Depois do Replicat do initial Load ter terminado, você deve apaga-lo e criar um novo Distribtuion, dessa vez Origem deploy Oracle e destino BigData:
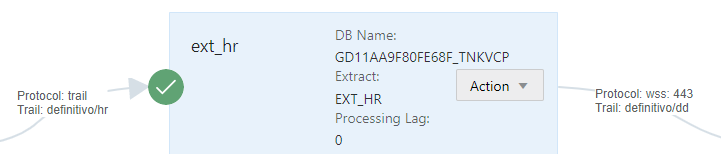
O trail de destino deve ser diferente do Trail usado no Receive de Initial Load.
Replicat definitivo
Depois que o o Replicat do initial Load terminar, basta criar um replicat baseado no Distribution que foi criado anteriormente, esse vai ser o nosso definitivo, o ponto importante aqui é que ele deve ser iniciado com o parâmetro ATCSN(Action -> Start With Options):
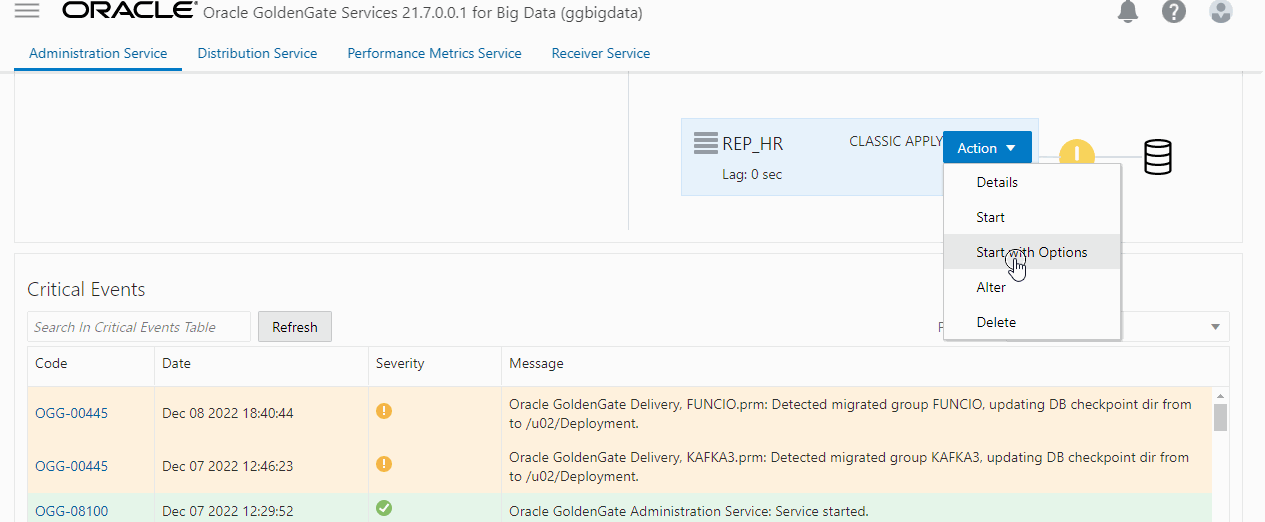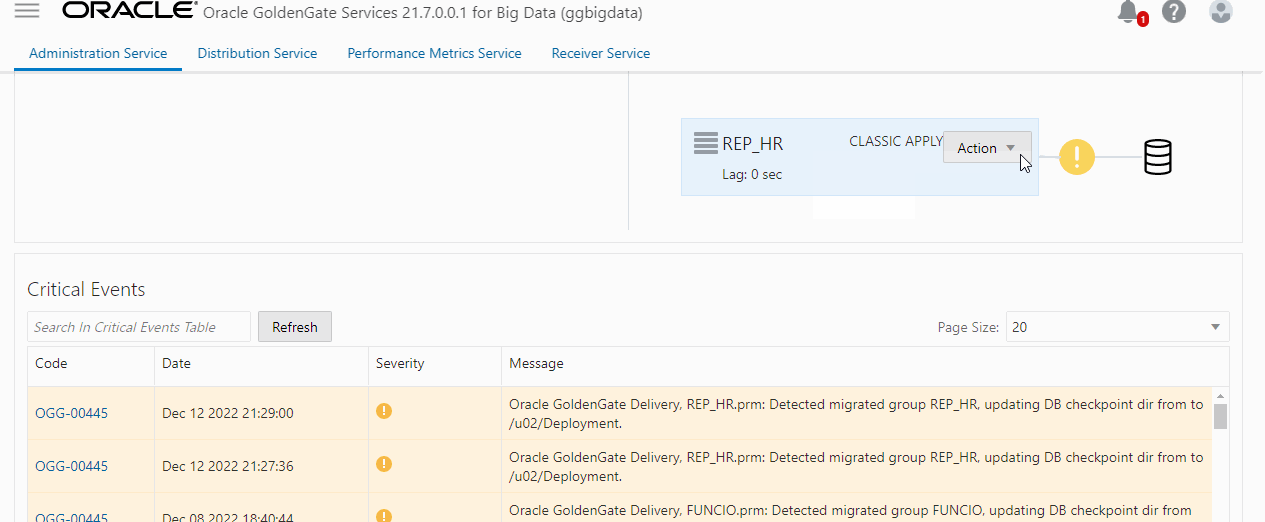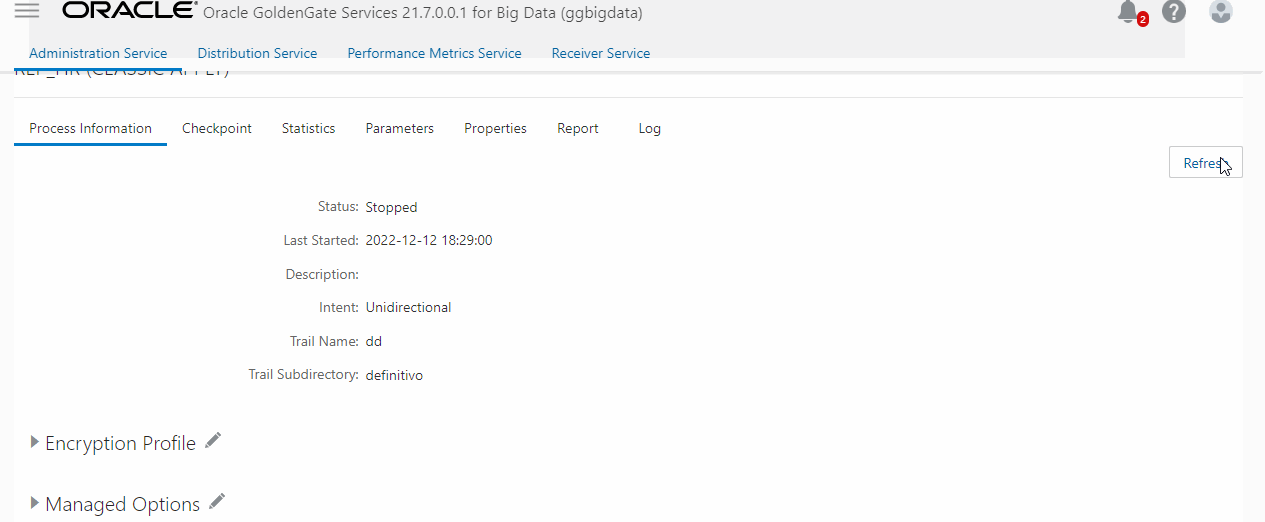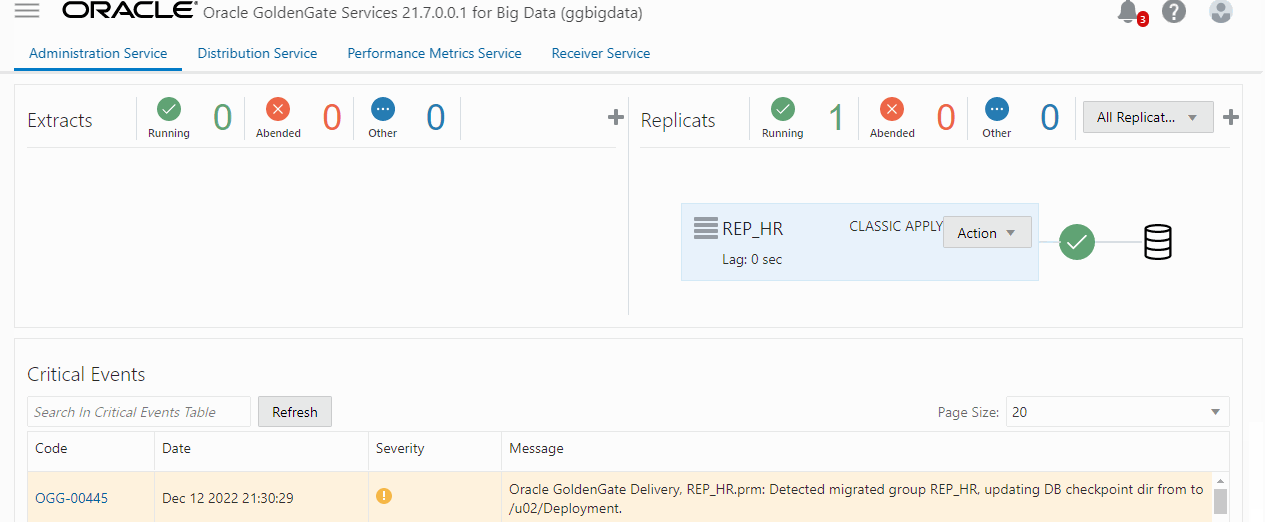
Esse parâmetro indica para o GG ignorar transações anteriores e aplicar a partir do SCN especificado.